


Manual de PSPP, software libre de Estadística
Índice del Artículo
VISTA DE VARIABLES

Con una interfaz gráfica parecida a la del SPSS, en la ‘Vista de Variables’ del paquete estadístico PSPP, se definen las variables del estudio, etiquetas de valor, tipos de variable: escala, ordinal (si importa el orden, por ejemplo variable tipo Likert) o nominales (categóricas). En el caso de que se exporten de otro programa (Excel, SPSS, etc), se pueden redefinir desde esta ventana. En la ‘Vista de Datos’, se puede manipular la base de datos con la que vamos a trabajar–a modo de una hoja de cálculo de Excel–con cada caso o registro por filas, y las variables o campos por columnas. En la ventana ‘Visor de resultados’ se pueden visualizar las tablas de nuestros análisis estadísticos.
FRECUENCIAS

Se genera la tabla de frecuencias de estadística descriptiva, los descriptivos por defecto y los opcionales con la barra de desplazamiento de ‘Descriptivos‘, en el cuadro de diálogo, el histograma con la curva normal, etc. Se puede omitir el mostrar la tabla de frecuencias (por ejemplo en el caso de variables continuas, donde normalmente carece de sentido), con el botón de opción ‘Nunca’ en la opción del botón de ‘Frecuencias‘.
EXPLORAR

Cuando se trata de realizar una comparativa de los estadísticos descriptivos de una variable dependiente de escala, normalmente media, mediana, coeficiente de variación (como el cociente de la desviación típica entre la media), respecto a una variable independiente explicativa de 2 o más niveles:

RECODIFICAR EN DISTINTAS VARIABLES

Como ocurre con SPSS, existe la posibilidad de recodificar variables en las mismas o diferentes variables. Se utiliza esta opción de comando para recodificar una variable continua en una categórica, o por ejemplo, en una dicotómica de valores 0:NO, 1:SÍ, muy utilizada como dependiente en regresión logística, o como independiente para cualquier tipo de regresión (múltiple o logística), único tipo de variables explicativas que pueden formar parte del análisis, junto a las continuas numéricas.
TABLAS DE CONTINGENCIA (TABLAS CRUZADAS DE LA CHI-CUADRADO)

Con las tablas cruzadas, se pueden gestionar los cruces en los que una de las variables en juego es nominal/cualitativa/categórica. Los residuos tipificados superiores a 1,96 o inferiores a -1,96 denotan significatividad, esto es, relación/dependencia entre el cruce de las 2 categorías de la celda:

TEST DE NORMALIDAD

Cuando se trata de estadística inferencial, uno de los pasos previos al contraste de hipótesis de los análisis estadísticos, es la comprobación del supuesto previo de normalidad en los datos de la variable de respuesta, para proceder de esta manera, desde un punto de vista paramétrico o no.
COMPARATIVA DE MEDIAS: T DE STUDENT

Una vez se comprueba que la prueba de normalidad de la variable dependiente de escala no es estadísticamente significativa, se puede llevar a cabo el test de igualdad de medias, para varianzas desconocidas pero supuestamente iguales (T-test), o cuando no se cumple la homogeneidad de varianzas, esto es, resulta significativa la prueba de homocedasticidad, y se utiliza la prueba de Welch:

El IMC se comporta de manera diferente en dispersión respecto al género (0,017< 0,05), mientras que no hay diferencias estadísticamente significativas en media para la variable de respuesta (0,149>0,05).
ANOVA DE 1 FACTOR


Al resultar estadísticamente significativo el test de homocedasticidad, habría que recurrir al equivalente no paramétrico, esto es, la prueba H de Kruskal-Wallis. En la tabla ANOVA se aprecian diferencias significativas entre las medias (se rechaza la hipótesis nula de que el IMC es el mismo para los 3 grupos de edad), lo que se parecía dislumbrar desde un punto de vista descriptivo. Al no haber pruebas de comparaciones múltiples (Post-Hoc), se puede recurrir a la T de Student, o a comprobar solapamientos entre los intervalos de confianza al 95%, para hacer comparativas de las medias de los grupos 2 a 2, y detectar las diferencias estadísticamente significativas.
REGRESIÓN MÚLTIPLE
REGRESIÓN LOGÍSTICA BINARIA
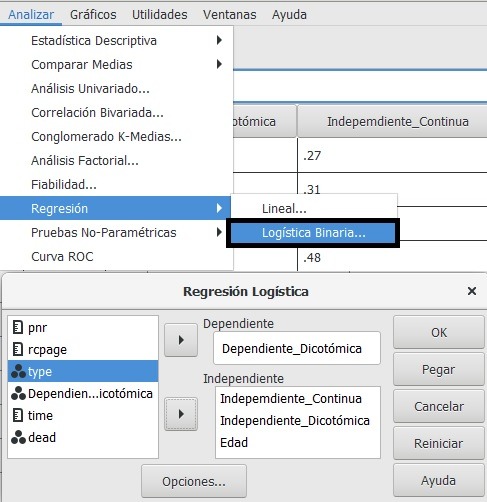

El modelo de regresión logística explica una proporción sensible de la variabilidad de la variable dependiente dicotómica, las 2 variables explicativas afectan significativamente a la probabilidad de ocurrencia de los casos catalogados con el valor 1 en la variable de respuesta (la independiente de tipo continuo hace incrementar 1,98 veces las probabilidad de ocurrir el valor 1).
LINK DE DESCARGA DEL SOFTWARE PSPP