Análisis Cluster con SPSS
El análisis de conglomerados (o clustering) es una técnica estadística utilizada para identificar grupos de elementos similares en un conjunto de datos por casos.
Índice del Artículo
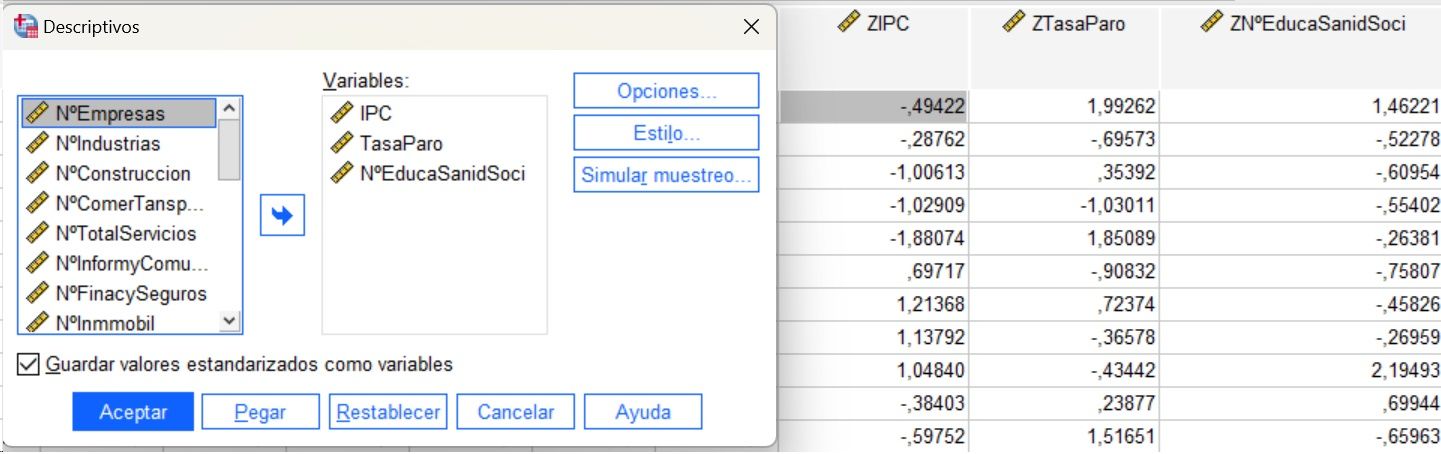
Guardar valores estandarizados
Se generan los variables tipificados, restando la media y dividiendo por la desviación típica, el SPSS lo hace de manera automática marcando el check-box de ‘Guardar valores estandarizados como variables’.
Conglomerado jerárquico y Dendograma
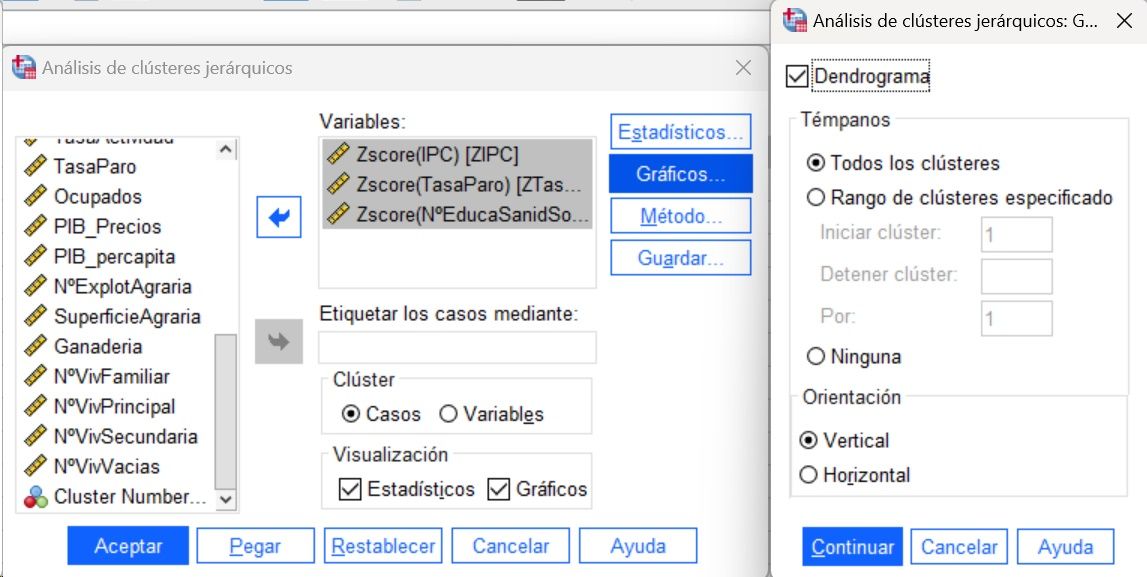
A través del método jerárquico de Ward y la medida de intervalo “distancia euclídea al cuadrado” se podría determinar el número de grupos/conglomerados/cluster más adecuados para la clasificación de los casos (las filas de nuestra base de datos). Los comandos de menú en SPSS: ‘Analizar > Clasificar > Clúster jerárquico’.
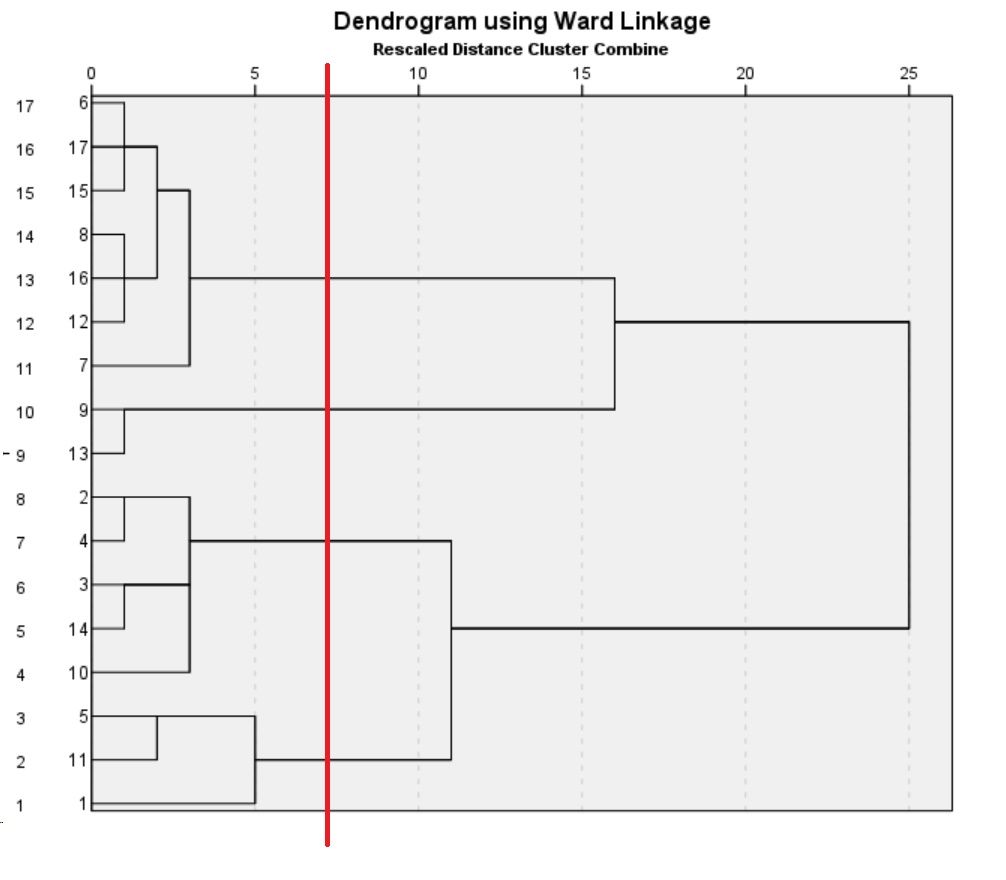
A través de la línea vertical en la representación gráfica del Dendograma, se puede determinar el numero de cluster, y siempre a partir del ángulo superior izquierda del mismo
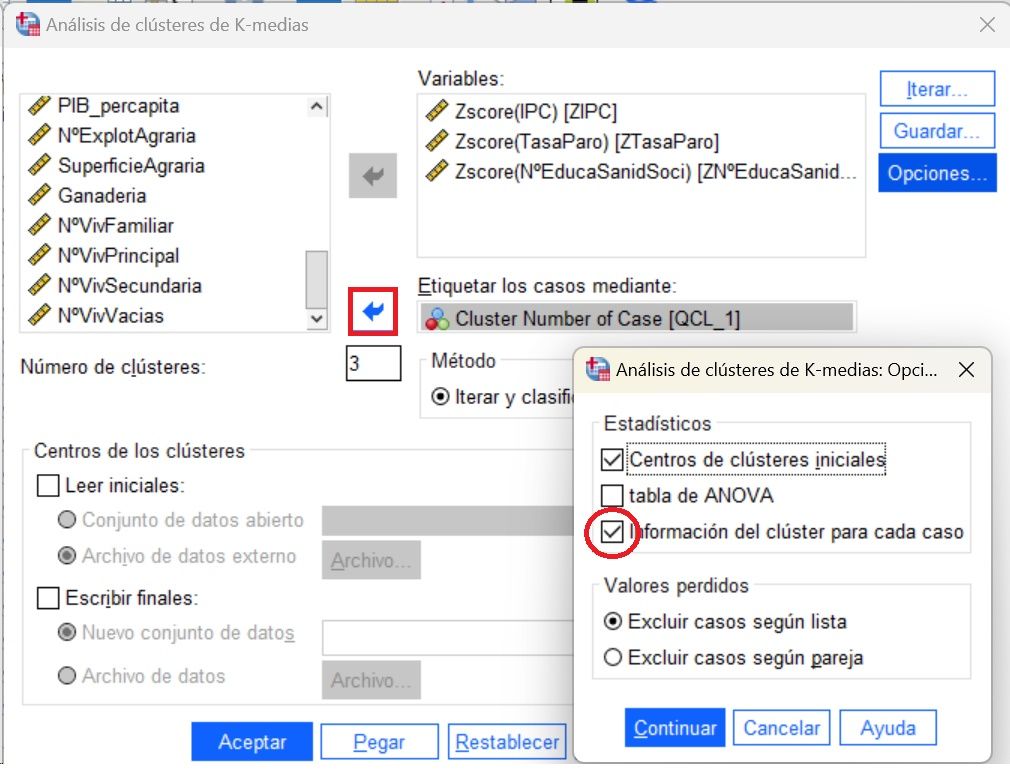
Cluster k-medias por conglomerado de pertenencia
En los botones de opción, se hace clic en Guardar, y en el cuadro de diálogo subyacente se marca la opción de Información del clúster para cada caso (clúster de pertenencia). Así, se genera una nueva variable al final de la base de datos .sav. con el clúster al que se asigna cada caso.
Se busca la mayor distancia de un caso al centro de su clúster de pertenencia y la comparamos con la menor distancia entre 2 conglomerados de la tabla ‘Distancias entre centros de conglomerados finales’. En el caso de que el primer valor sea menor que el segundo, se puede afirmar que de alguna manera estarían correctamente clasificados.
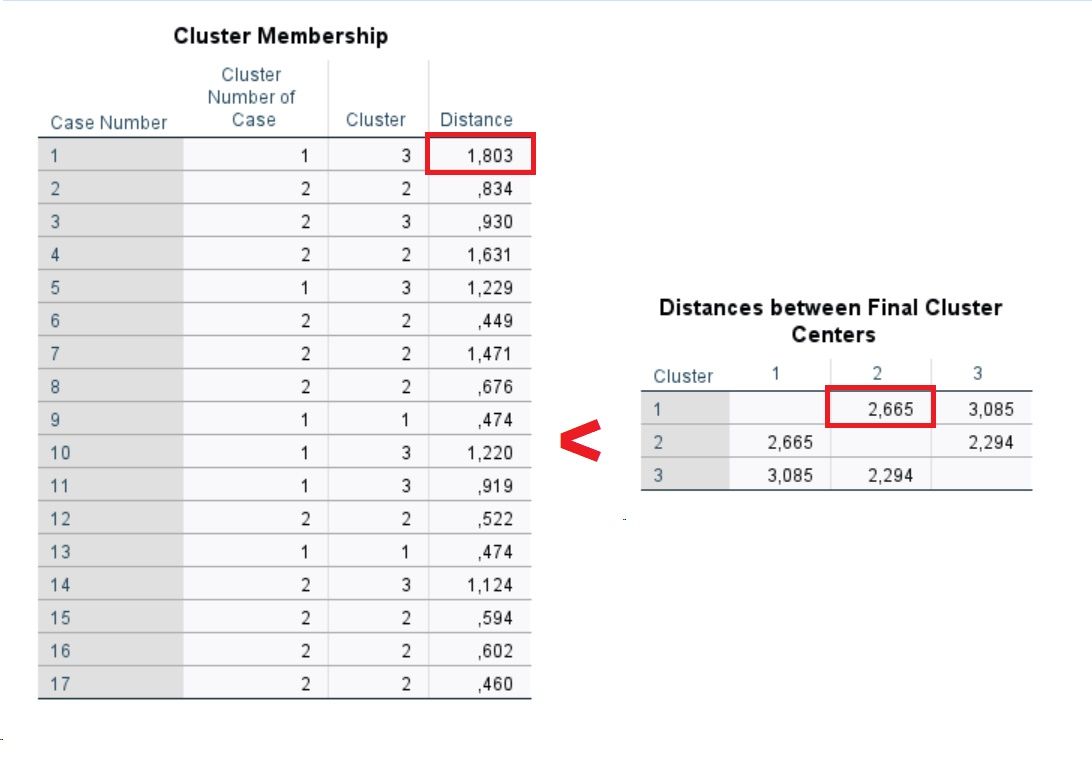
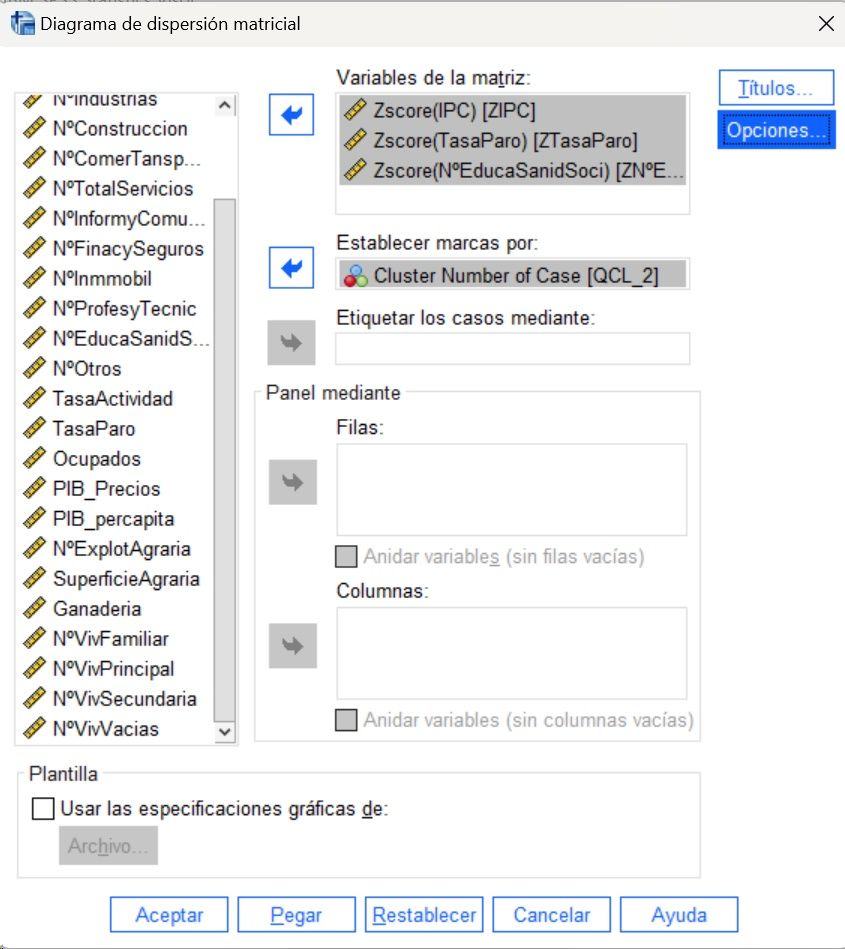
Diagrama de Dispersión 3D segmentado por nº de Cluster
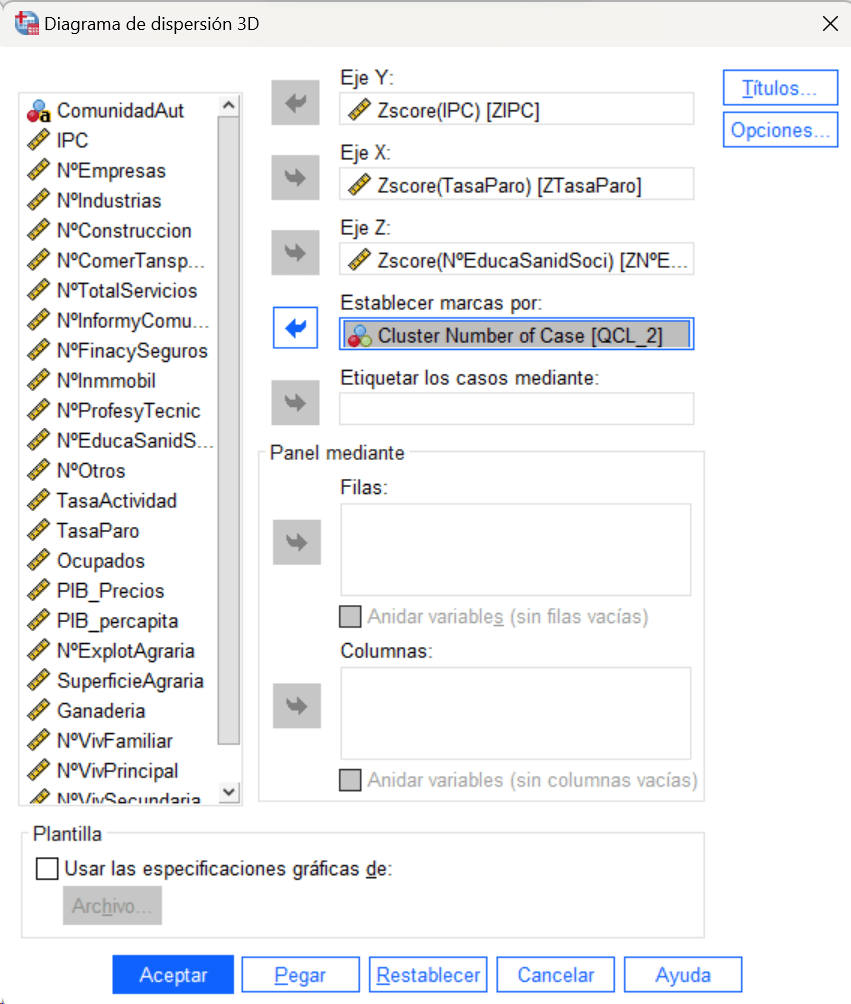
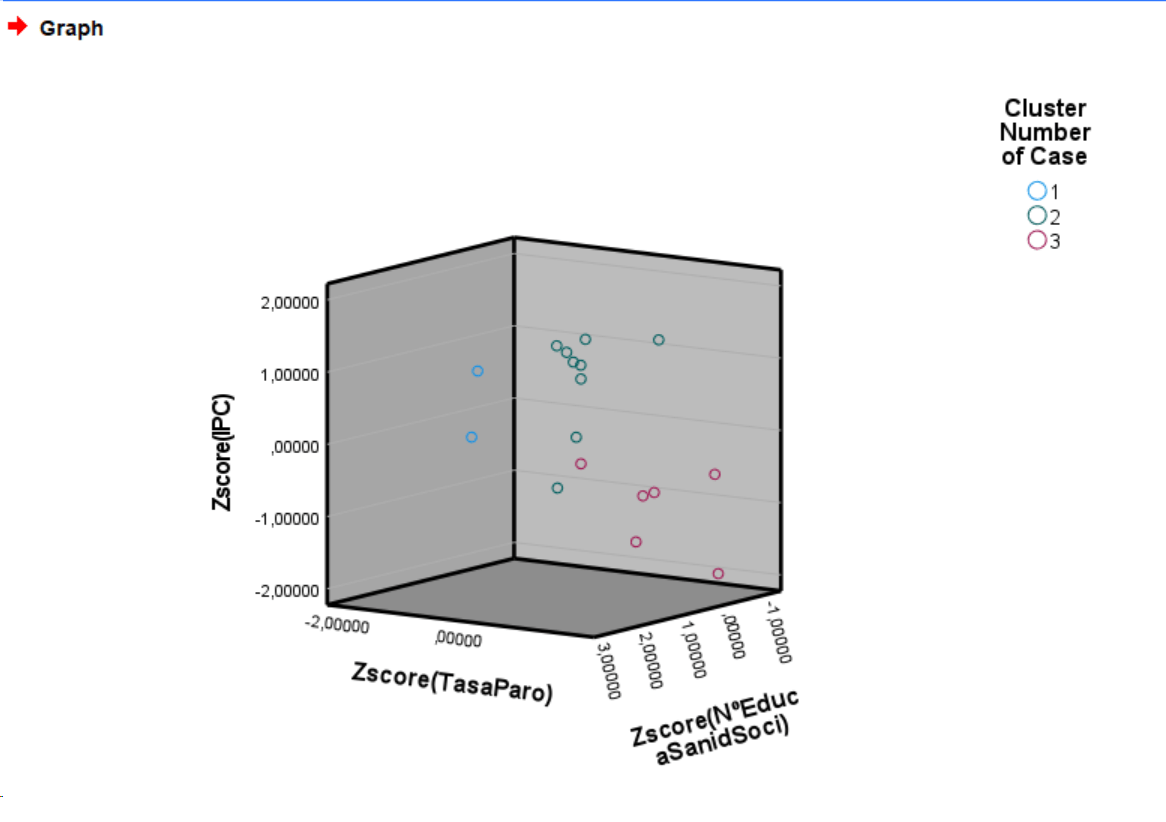
Gráfico de Dispersión Matricial

Análisis de cluster para identificar segmentos de clientes con patrones de comportamiento similares con Chat GPT