

Análisis de Conglomerados

También conocido como Análisis Cluster, se trata de un conjunto de técnicas multivariantes del tipo descriptivo-no inferencial, cuya principal finalidad es agrupar observaciones basándose en las características similares que poseen. Con él se pretende identificar grupos homogéneos de casos u observaciones de la muestra. Los clusters o conglomerados resultantes, deben mostrar un alto grado de homogeneidad interna dentro de los conglomerados (within), además de un alto grado de heterogeneidad externa entre conglomerados (between). En Análisis de Conglomerados los grupos no están definidos previamente, como ocurre en el Discriminante; en el Factorial se agrupan variables, en el Cluster son las observaciones/casos las que se tienden a agrupar.
En una primera fase se construye la matriz de distancias o similaridades, en la que tanto filas como columnas son las observaciones, y las celdas son una medida de la similitud entre las mismas. Estas semejanzas se pueden medir de muchas maneras, como pueden ser la correlación entre las observaciones, con la distancia euclídea, etc.
3 Tipos de análisis de conglomerados:
- Análisis de Conglomerados Jerárquico
- Análisis de Conglomerados de K-medias
- Análisis de Conglomerados Bi-etápico
Índice del Artículo
Análisis de Conglomerados Jerárquico
Partiendo siempre de la limitación en cuanto al número de individuos o casos, con el método de clasificación jerárquico, en cada paso del algoritmo es sólo un individuo o elemento de la muestra el que cambia de grupo. Si un caso ha sido asignado a un grupo ya no cambia más de grupo. Este método jerárquico es ideal para determinar el número óptimo de conglomerados existente, y de cuales individuos en concreto se componen dichos clusters. Tiene sentido únicamente cuando el número de observaciones o elementos de la muestra no es muy grande.


Interpretación Dendograma: En primer lugar se forma un conglomerado del modelo 8 con el 11, seguido del cluster del modelo 6 con el 7, y así sucesivamente, hasta tener 2 conglomerados finales, el último formado por los modelos 6, 7, 1 y 10.

Método de Ward usando un nº determinado de conglomerados


Guarda una nueva variable con el número del conglomerado de pertenencia en función del algoritmo de la distancia euclídea con el método de Ward, para poder hacer posteriormente comparativas de medias a partir de la T de Student si se trata de 2 medias, y Tabla ANOVA si se comparan las medias de la variable dependiente continua, en función de 3 o más conglomerados (variable independiente o factor). También se pueden generar estadísticos descriptivos en función de la variable independiente cluster de pertenencia, y detectar los atípicos con el gráfico de Box-Plot.
Representación Gráfica de Conglomerados
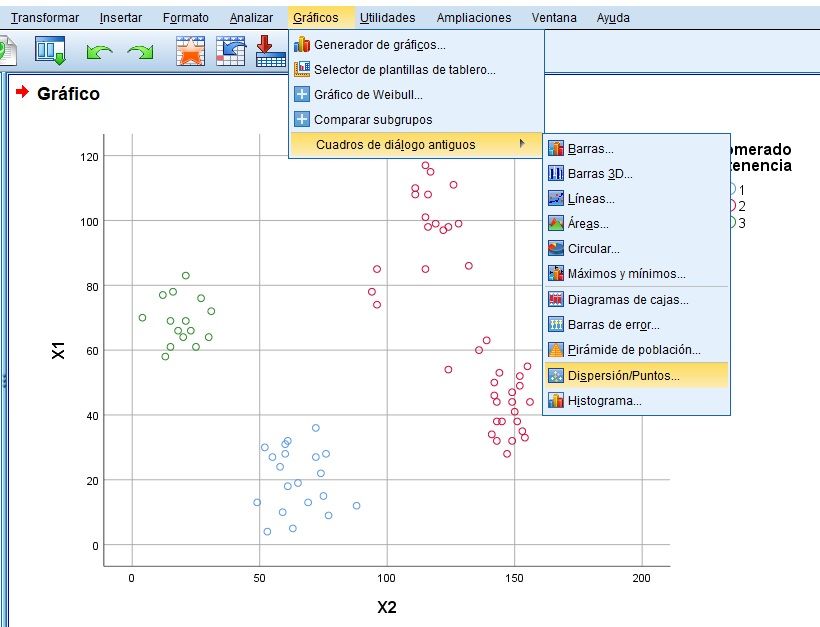


Análisis de Conglomerados de K-medias
Se trata de un método de clasificación no jerárquico en el que el número de clústeres que se van a formar es determinado a priori. Puede resultar conveniente indagar qué resultados se obtienen con diferentes números de conglomerados. Sólo puede ser aplicado a variables cuantitativas y puede llevarse a cabo con tamaños muestrales grandes. Cada caso es asignado a un clúster en base a que su distancia con respecto al centroide sea mínima.
