

Estadística con Excel
Índice del Artículo
Análisis Estadístico con Excel

¿Hasta donde se puede llegar en Análisis de Datos con Excel?
Cuáles son las limitaciones de llevar a cabo análisis de estadística con Excel, así como contrastes estadísticos sin necesidad de utilizar un software específico, realizando dichos test con la herramienta Análisis de Datos de ‘opciones complementos’, del propio Microsoft Excel.
Instalación del complemento de Análisis de Datos

Generar muestras aleatorias
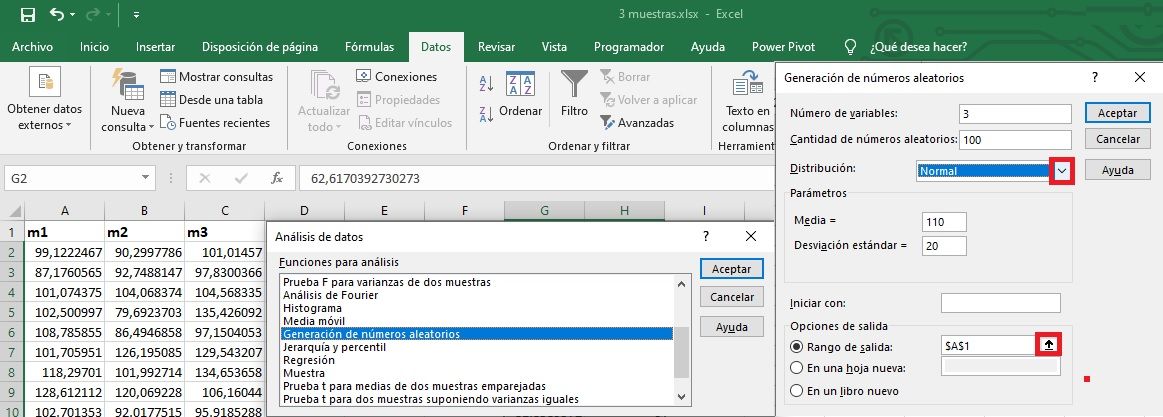
Existe la posibilidad de generar datos aleatorios parecidos a los de nuestra de base de datos, incluso antes del proceso de recopilación de datos (o añadir ficticios a los que ya tenemos), para poder ir investigando el/los análisis estadístico/s más adecuado/s en nuestro estudio (TFM, TFG, abstract científico, paper, publicación, informe, etc).
Descriptivos
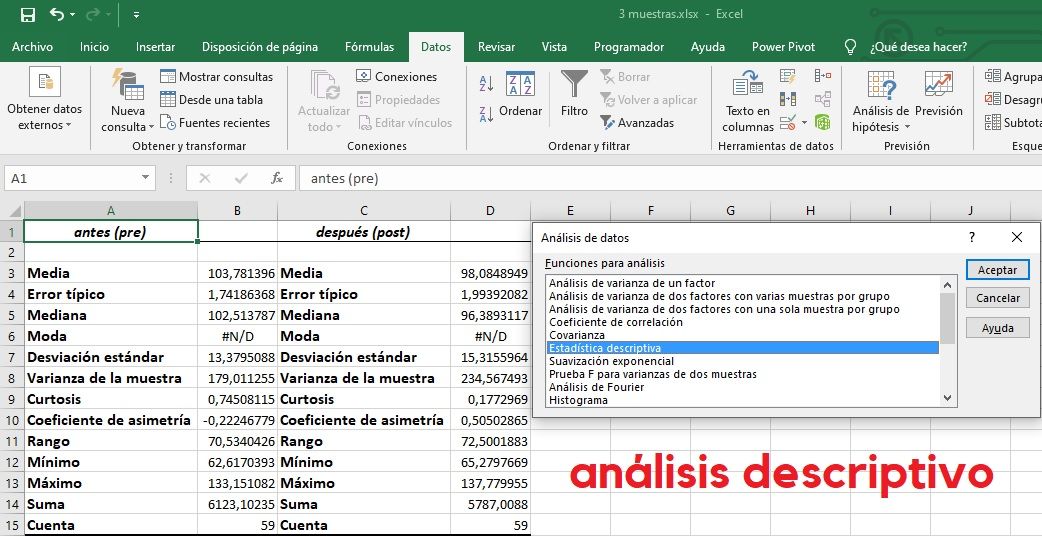

El Coeficiente de Variación (CV) es una medida de la representatividad de la media (<0,3), cuanto más próximo a 0, menor dispersión. También sirve para comparar dispersiones (variabilidades) de 2 variables medidas en las mismas o diferentes unidades. En el caso de no cumplimiento del supuesto de normalidad, la medida de dispersión más aconsejable es el recorrido intercuartílico (RI), diferencia entre el tercer y el primer cuartil, es decir la amplitud de la caja del Box-Plot.
Diagrama de caja o Box-Plot

Gráfico de caja para detectar valores atípicos (outliers) y para intuir Normalidad en los datos de la/s variable/s de respuesta dependiente en estudio, en el caso se situarse la Mediana (línea horizontal) en el centro de la caja, y de esta modo, proceder con los correspondientes test paramétricos, como la T de Student de comparativa de 2 medias, o la Tabla ANOVA de más de 2 medias.

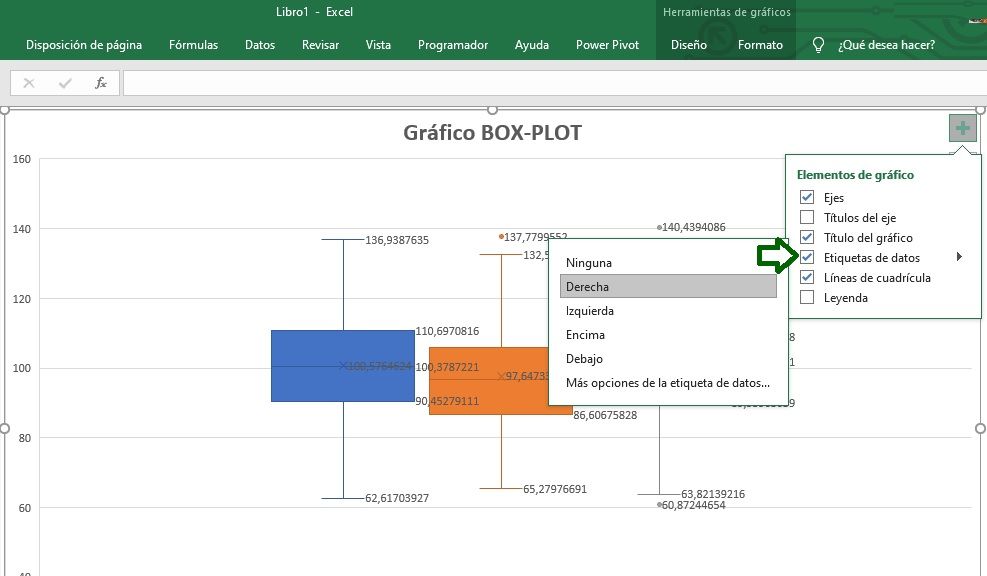

Intuición de cumplimiento de supuesto de Normalidad

Si los valores del coeficiente de asimetría que nos proporciona la opción de ‘Estadística Descriptiva’ de Análisis de datos, están próximos a 0, se puede intuir normalidad en la distribución de los datos. También la mediana en el centro de la caja del gráfico Box-Plot del apartado anterior, o con una simulación del gráfico PP Plot, a partir de la línea de tendencia de los valores de la variable de respuesta, si los valores gráficamente se asemejan a la línea, se puede presuponer normalidad:

Por último señalar que si el tamaño muestral es lo suficientemente grande, se puede proceder desde un punto de vista paramétrico, suponiendo normalidad en la distribución de la muestra.
CONTRASTES DE HIPÓTESIS PARAMÉTRICOS

Prueba de Homogeneidad de Varianzas (Homocedasticidad)
Hipótesis nula: Homocedasticidad en las 2 muestras
Hipótesis alternativa: Heterocedasticidad

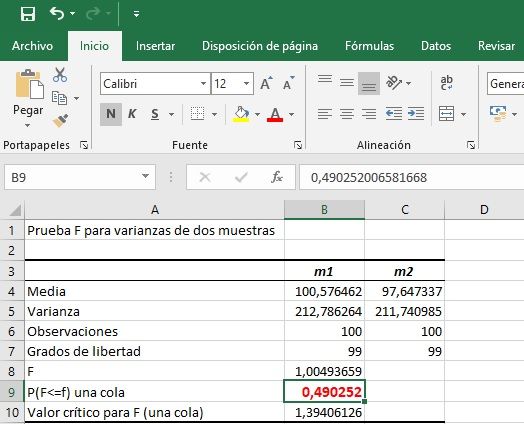
Como el valor de probabilidad asociado al contraste de homogeneidad de varianzas es mayor de 0,05, no se puede rechazar la homocedasticidad entre ambas muestras, se comportan de la misma manera en variabilidad (son homogéneas), siempre trabajando con un nivel de confianza del 95%, que fija el/la investigador/a.
T de Student de comparativa de 2 medias de muestras independientes

Este es el planteamiento de la hipótesis nula (sobre la que se llevan a cabo las conclusiones) y la alternativa (la del investigador), para el caso de T de Student muestras independientes. Hay 2 maneras de actuar en función del cumplimiento del supuesto de homocedasticidad o no.
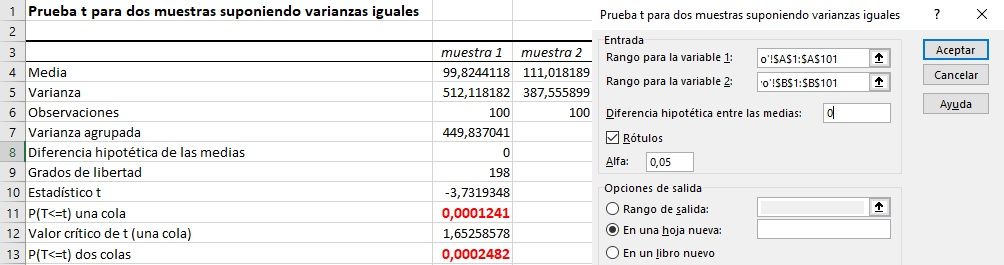
Varianzas homogéneas
Varianzas diferentes

Resultan estadísticamente significativos tanto el test de homogeneidad de varianzas, como el de comparativa de medias de la T de Student, pues en ambos casos la probabilidad asociada es menor de 0,05. Los resultados muestrales pueden extrapolarse a la población haciendo inferencia, el comportamiento es diferente tanto en variabilidad como en media, pues ambos test son significativos.
T de Student de comparativa las medias de 2 muestras relacionadas



En el caso del test bilateral (2 colas), el p-valor es muy cercano al nivel de significación de 0,05 (0,047), por lo que quizá sería conveniente aumentar el tamaño muestral, para un resultado concluyente. En el caso unilateral (1 cola), esto es, unilateral inferior o superior, el contraste resulta estadísticamente significativo, pues el valor de probabilidad (0,023) es sensiblemente inferior al 5%. Este p-valor también se podría obtener dividiendo la probabilidad asociada del bilateral entre 2.
ANOVA de un Factor

HIPÓTESIS NULA: Todas las medias son iguales
HIPÓTESIS ALTERNATIVA (la del investigador): algún par de medias difieren
ANOVA NO SIGNIFICATIVO

Al tratarse de un valor de probabilidad asociado a la Tabla Anova mayor de 0,05, no se aprecian diferencias estadísticamente significativas entre las medias de las 3 muestras, incluso aunque descriptivamente se pueda intuir que la media de la muestra 2 (97,64), es sensiblemente inferior a la media de las otras 2 muestras. No sería necesario por lo tanto llevar a cabo pruebas de comparaciones múltiples para detectar diferencias entre las medias.
ANOVA SIGNIFICATIVO

En este caso los resultados arrojan diferencias estadísticamente significativas (p-valor <0,05) en al menos la comparativa de un par de medias. Desde un punto de vista descriptivo parece que la media de la muestra 2 es significativamente superior, lo que se tiene que corroborar con la correspondiente prueba de T de Student entre 2 muestras, ya que la herramienta de Excel ‘Análisis de datos’, carece de pruebas Post Hoc de comparaciones múltiples, las cuales reducen los errores de tipo I y de tipo II en estos Test.
Comparaciones múltiples (opción)
T de Student muestra 1 versus muestra 2 (hipótesis de que la media de la muestra 2 es mayor)
Se detectan diferencias estadísticamante significativas (p-valor<0,05), se comprueba desde un punto de vista analítico que la media de la muestra 1 es sensiblemente inferior a la media de la muestra 2, lo que se intuía desde un punto de vista descriptivo.
T de Student muestra 2 versus muestra 3 (hipótesis de que la media de la muestra 2 es mayor)

Se vuelven a detectar las diferencias estadísticamente significativas que se observaban descriptivamente, la probabilidad del estadístico de contraste de la T de Student es menor del 5%.
ANOVA de 2 Factores


Tanto los factores como efectos principales como la interacción de los mismos resultan estadísticamente significativos.

Análisis de Correlaciones

En función de los valores del coeficiente de correlación lineal de Pearson, se puede interpretar la relación/dependencia/asociación lineal entre las variables continuas, aquí la herramienta de Análisis de Datos tiene la limitación de que no proporciona un p-valor de significatividad estadística, ni el coeficiente de correlación de Spearman para el cruce de variables de tipo ordinal.

Regresión Lineal Simple y Regresión Múltiple (GLM)
Regresión Simple

La % de variabilidad de la variable de respuesta explicada por el modelo es del 17,35% (R cuadrado), se considera conveniente el llevar a cabo una regresión lineal simple porque el valor de probabilidad asociada a la Tabla Anova de la regresión es estadísticamente significativo. La variable independiente es estadísticamente significativa, pues su p-valor es menor de 0,05. La interpretación de la pendiente/coeficiente Beta, es que cuando la variable X1 se incrementa en una unidad, la variable dependiente Y aumenta 39,6 veces.

Regresión Múltiple


Con la herramienta de Análisis de Datos no se pueden comprobar (limitación) los supuestos previos de partida de independencia de los errores con el estadístico de Durbin-Watson, y de no multicolinealidad a través de FIV mayores de 1, aunque este último supuesto se puede corroborar a través de la matriz de correlaciones del apartado anterior, no debiendo existir mucha relación entre las variables independiente explicativas de la regresión múltiple.
Se prueban diferentes modelos, a partir de la correlación de la variable de respuesta con las covariables, y a partir de un valor del coeficiente de determinación ajustado superior a 0,7 (o lo que es lo mismo, proporción de variabilidad explicada por el modelo mayor del 70%). Se incluyen en el GLM final las variables estadísticamente significativas, cuyo valor de probabilidad (en rojo) sea menor de 0,05. Los valores de los coeficientes Betas nos dan una medida de como aumenta o disminuye la variable dependiente, cuando aumenta la independiente en una unidad, permaneciendo el resto de las variable como constantes.
TABLAS DINÁMICAS
Configuración de campo de valor

Siempre con el foco de entrada en una celda de la tabla dinámica, se puede hacer clic en la variable numérica que se coloca en la sección de ‘Valores’, y con la opción ‘Configuración de campo de valor’, obtener estadísticos descriptivos de manera dinámica, como el promedio, desviación típica, varianza, etc.
Números índice

Cálculo del porcentaje de aumento o disminución de la variable numérica en un periodo de tiempo determinado (año), respecto a otro año que se toma como base para el cálculo del número índice (%).