


Excluir valores missing en Tabla Cruzada de la Chi-cuadrado
¿Cual es la manera de actuar a ls hora de excluir los valores missing (perdidos: 99) en el software estadístico SPSS , para el caso concreto de las Tablas Cruzadas (Tablas de Contingencia) de la Chi-cuadrado, para el cruce (correlación %) de variables categóricas (nominales). No doy con el tutorial de ello, y no se me ha dado nunca el caso.
Índice del Artículo
Recodificar en distinta variable

Los valores ‘SI’ se transforman en 1, los valores ‘NO’ se convierten en 0, los missing 99 siguen siendo missing, y el resto se convierten también en 99 (por ejemplo ‘No procede’ o similar).
Seleccionar casos si cumplen determinada condición

Seleccionar casos de la variable recodificada*, si cumplen la condición con el operador lógico: | (ó=disyunción) y con el operador: & (y=conjunción), en el ejemplo, se queda con los casos que tienen valor ‘NO’ y ‘SI’.
*hacer doble clic en la variable recodificada en el panel de la izquierda, en lugar de escribir el nombre, pues puede dar problemas.
Tablas Cruzadas con la Chi-cuadrado
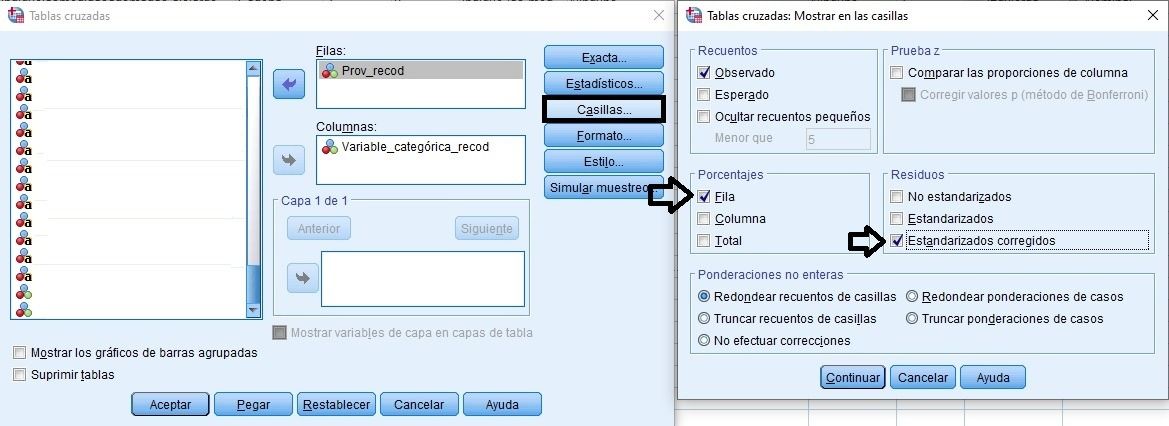
Las casillas de verificación a marcar del cuadro de diálogo de las Tablas Cruzadas en SPSS, en el cruce de variables categóricas son las de los %, según se quieran reflejar por filas y columnas, y las de los residuos tipificados, cuyos valores mayores que 1,96 o menores de -1,96, denotan diferencias estadísticamente significativas en en cruce de categorías.
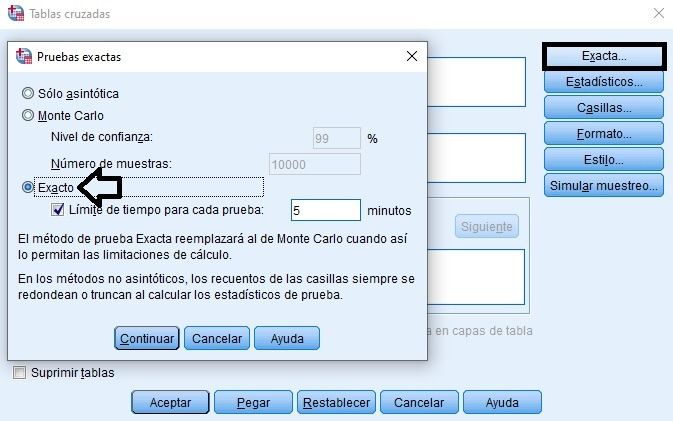
En el caso de superar el % del 20 de frecuencias esperadas menores de 5, utilizamos la significación exacta, más apropiada en este tipo de situaciones:
Redacción de resultados tipo TFM, TFG, Abstract.
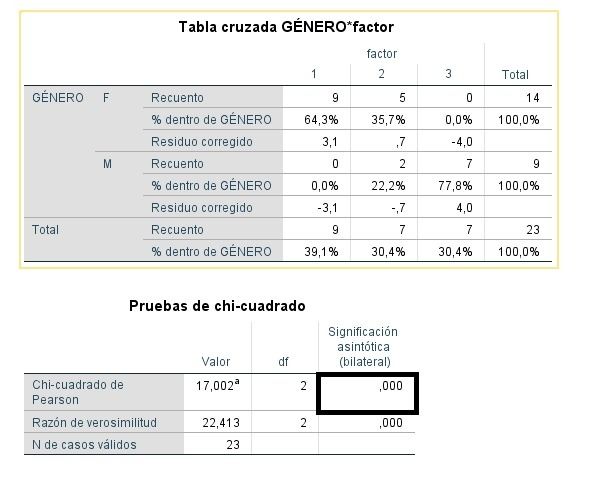
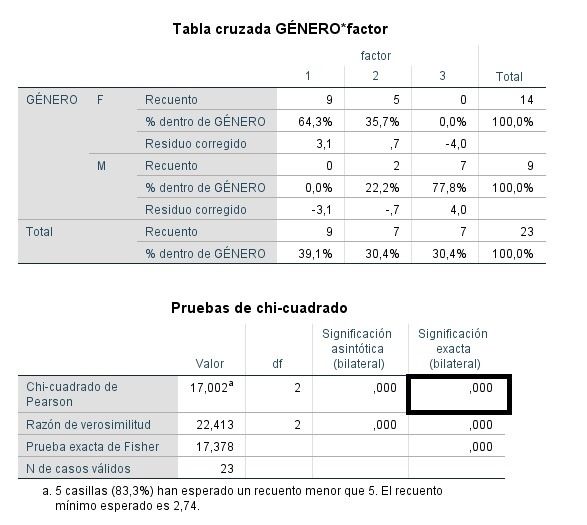
Se ha realizado una prueba χ2 para analizar la asociación entre la ‘variable categórica 1’ y la ‘variable categórica 2’. Los resultados muestran que ambas variables están relacionadas [χ2=17,002, p<.001], existiendo un mayor porcentaje de mujeres que se inclinan por el factor 1, y un mayor porcentaje de hombres que afirma decantarse por el factor 3.
Limitaciones de la Prueba de la Chi-cuadrado
- Para llevar a cabo el contraste de independencia se suele usar el estadístico Chi-cuadrado de Pearson. Su cálculo se basa en la diferencia entre las frecuencias observadas para cada par de categorías de las variables (casillas), y las frecuencias esperadas. Para que se pueda considerar como correcto el p-valor calculado por el estadístico, se debe cumplir el que las frecuencias esperadas inferiores a 5, deben ser menores del 20%. En caso de violación de este supuesto, se debe recurrir a una prueba que no incluya aproximaciones, como el Test exacto de Fisher, sobre todo si se trata de muestras pequeñas-
- Si se trata de muestras excesivamente grandes, el test de independencia dará resultados estadísticamente significativos incluso donde se pueda considerar que las diferencias no sean en realidad clínicamente relevantes.
- Si las variables contienen muchas categorías, posiblemente la prueba no resulte de mucho interés, ya que es lógico esperar que se encuentren diferencias. Esto suele ocurrir si por ejemplo una de las variables es numérica, y no hemos recodificado la variable para agruparla en unos pocos intervalos.
- Si una de las variables que intervienen en el cruce es numérica u ordinal, posiblemente queramos hacer algo más que contrastar la simple independencia, con test más potentes desde un punto de vista analítico, y usar pruebas tipo la t de Student, el Anova, o sus equivalentes no paramétricos, estos últimos más aconsejables para variables dependientes de tipo ordinal (Likert), o cuando no se cumplan los supuestos de normalidad y homocedasticidad.
- Para comparar proporciones (%) de categorías de las variables, siempre podemos recurrir al contraste de proporciones, para detectar posibles diferencias, siempre trabajando con el nivel de confianza de la investigación.
Prueba exacta de Fisher
Ho: Las 2 variables dicotómicas son independientes; Ha: Existe algún tipo de relación entre ellas.

No se puede rechazar la hipótesis nula de que no hay relación entre las 2 variables, pues el p-valor es mayor del 5%, siempre trabajando con un nivel de confianza del 95%, el más común en este tipo de test, de cruce de variables categóricas. El que el valor de la significación unilateral esté tan cercano al valor frontera del 5% (0,05), puede inducir a pensar que al aumentar el tamaño muestral, tales diferencias pueden mostrarse como significativas.