

Modelos de regresión múltiple jerárquica
La regresión múltiple jerárquica es una técnica estadística que permite evaluar cómo diferentes bloques de variables explicativas (predictoras) contribuyen al modelo de regresión en distintas etapas. Se utiliza cuando se quiere entender el efecto incremental de grupos de variables sobre una variable dependiente, controlando primero por otras.
Supuestos de partida
✅ Supuestos fundamentales de la regresión múltiple:
| Nº | Supuesto | Descripción | Cómo comprobarlo |
|---|---|---|---|
| 1 | Linealidad | La relación entre las variables independientes y la dependiente debe ser lineal | Diagramas de dispersión, gráficos de residuos |
| 2 | Independencia de los errores | Los residuos (errores) deben ser independientes entre sí | Prueba de Durbin-Watson entre 1.5 y 2.5 |
| 3 | Homoscedasticidad | La varianza de los errores debe ser constante en todos los niveles de las variables independientes | Gráfico de residuos vs predichos, test de Breusch-Pagan |
| 4 | Normalidad de los errores | Los residuos deben seguir una distribución normal (no las variables, sino los errores) | Histograma de residuos, QQ plot, prueba de Shapiro-Wilk |
| 5 | No multicolinealidad | Las variables independientes no deben estar excesivamente correlacionadas entre sí | VIF (Variance Inflation Factor) próximo a 1, matriz de correlaciones |
| 6 | Ausencia de valores atípicos influyentes | No debe haber casos que influyan desproporcionadamente en el modelo | Leverage, distancia de Cook, gráfico de influencia |
La multicolinealidad se refiere a la alta correlación entre las variables independientes en un modelo de regresión múltiple, las variables explicativas de alguna manera aportan información redundante. La tabla de estadísticos de colinealidad proporciona indicadores para evaluar este problema: el VIF (Factor de Inflación de la Varianza) y la Tolerancia (1/VIF). Generalmente, un VIF > 5 o 10 (o una Tolerancia < 0.2) se considera indicativo de un problema de multicolinealidad importante.
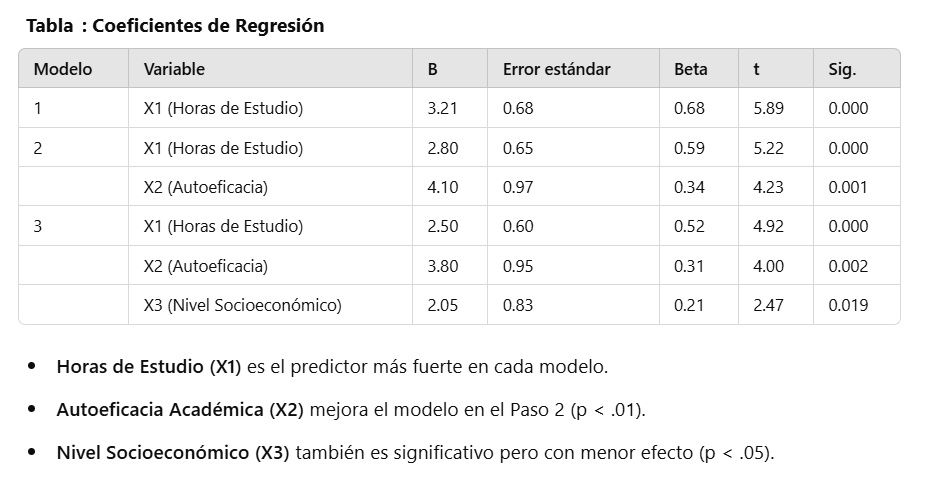
Dependiendo del investigador/a, se puede reflejar un modelo final con todas las variables o solo con las estadísticamente significativas. Quizá lo más correcto es que el modelo final tenga tan solo las significativas, que son buenas predictoras del ajuste de regresión múltiple jerárquica.
El R² ajustado (R cuadrado ajustado) es una medida estadística que corrige el R² (coeficiente de determinación) teniendo en cuenta el número de predictores en un modelo de regresión. Es especialmente útil en regresión múltiple y jerárquica porque penaliza la inclusión de variables irrelevantes. Refleja la proporción de variabilidad de la variable dependiente explicada por el modelo.
Coeficientes Estandarizados
Para comparar la magnitud de la influencia de las variables independientes (factores) en la variable de respuesta dentro del modelo de regresión, se utilizan los coeficientes estandarizados (‘Standard Estimate’). El coeficiente estandarizado indica cuántas desviaciones estándar cambia la variable dependiente por cada desviación típica que cambia la variable independiente, permaneciendo el resto de las variables como constantes. La variable con el mayor valor absoluto en el coeficiente estandarizado es la que tiene mayor peso en la regresión.
¿Cómo interpretar los coeficientes estandarizados para identificar la variable con mayor influencia en un modelo de regresión?.
🧪 Ejemplo: Predicción del rendimiento académico de estudiantes
Supongamos que estás analizando qué factores explican el rendimiento académico (medido por la nota final del curso, de 0 a 10) de un grupo de estudiantes. Planteas el siguiente modelo de regresión:
📌 Variable dependiente (VD):
Nota final del estudiante.
📌 Variables independientes (VI):
Horas de estudio por semana.
Asistencia a clase (en %).
Nivel de estrés (medido en una escala de 1 a 10).
✅ Interpretación: ¿Qué variable tiene más influencia?
Para determinar cuál variable tiene mayor influencia sobre la nota final, comparamos el valor absoluto de los coeficientes estandarizados:
|0.55| (horas de estudio)
|0.30| (asistencia)
|0.65| (estrés)
🟢 Conclusión:
La variable con mayor influencia sobre la nota final es el nivel de estrés, ya que tiene el mayor valor absoluto del coeficiente estandarizado (-0.65).
Esto indica que, manteniendo las demás variables constantes, un aumento de 1 desviación estándar en el nivel de estrés se asocia con una disminución de 0.65 desviaciones estándar en la nota final.
💡 ¿Por qué usamos coeficientes estandarizados?
Porque permiten comparar el peso relativo de diferentes variables, incluso si están en distintas escalas (por ejemplo, horas, %, y escala de 1 a 10). Así sabes cuál variable «pesa más» en la predicción, sin importar las unidades.