

Regresión Logística Binaria con SPSS

Regresión Logística Binaria para predecir la probabilidad de ocurrencia de una determinada variable dependiente dicotómica respecto a los grupos que forman otras variables independientes, categóricas y/o continuas, y en el caso de nominal con varias categorías, recodificadas en dummy (dicotómica). Establece un modelo de predicción o ajuste logit, muy indicado, por consiguiente, en estudios de grupos en Bioestadística o Ciencias Sociales, para determinar la probabilidad de ocurrencia de enfermedades, el efecto positivo o no de tratamientos (0:NO; 1:SI), funcionamiento o no de una política, o de una campaña de marketing, etc.

Las variables de tipo categórico/nominal, como puede ser el género, se definen aparte. Las variables que tengan más de 2 categorías, si se consideran de vital importancia para nuestro análisis estadístico, se recodifican de manera especial en variables dummies, dicotómicas de valores 0 y 1.
¿Cómo recodificar Variables DUMMY en SPSS?
Para poder introducir una variable nominal de este tipo, que tiene tres categorías (o más), en el modelo debemos recurrir a la categorización “dummy”, que consiste en la generación de variables dicotómicas ficticias para las distintas categorías de la variable. El esquema de codificación que se utiliza para crear, y por tanto, recodificar en ‘dummy’ un variable categórica u ordinal con más de 2 categorías (ejemplo: Nivel de Estudios), teniendo en cuenta que la categoría de referencia es “Estudios Primarios”, para que pueda entrar a formar parte de la regresión logística binaria es de la forma, es decir se generan 2 variable ficticias para 3 categorías, 3 para 4 categorías, permaneciendo la categoría omitida como variable de referencia:
Primaria | 0 | 0 |
Secundaria | 1 | 0 |
Universidad | 0 | 1 |
Luego al disponer de 3 categorías en la variable nivel de estudios, generamos 2 variables, ‘Secundaria’ y ‘Universidad’, siempre se crean tantas dummies como el número de categorías menos 1. Si el individuo pertenece a la categoría ‘Primaria’, le damos valor 0 a cada una de estas 2 dummies creadas, y la interpretación recae sobre la variable que se ha tomado como referencia, esto es, la que se omite, en este caso ‘Primaria’.
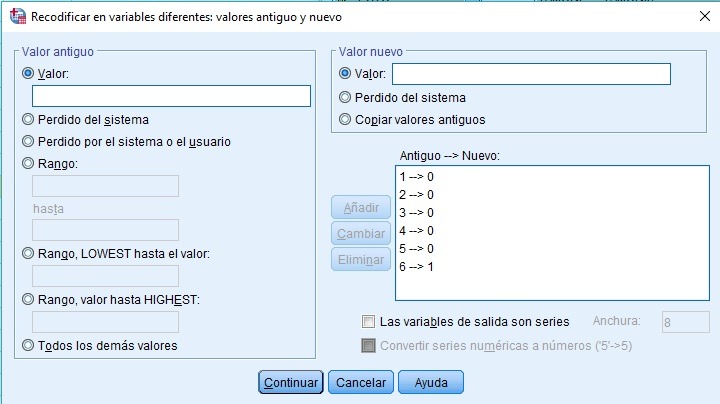
RECODIFICAR EN DISTINTAS VARIABLES
Se procede a generar 2 variables dummies nuevas, mediante la secuencia de comandos Transformar: Recodificar en distintas variables.

Recodificar en distintas variables con SPSS, variable con 6 categorías se recodifica en 5 variables dummies, tomando como referencia la primera categoría…
Modelo de Regresión Logística Binaria
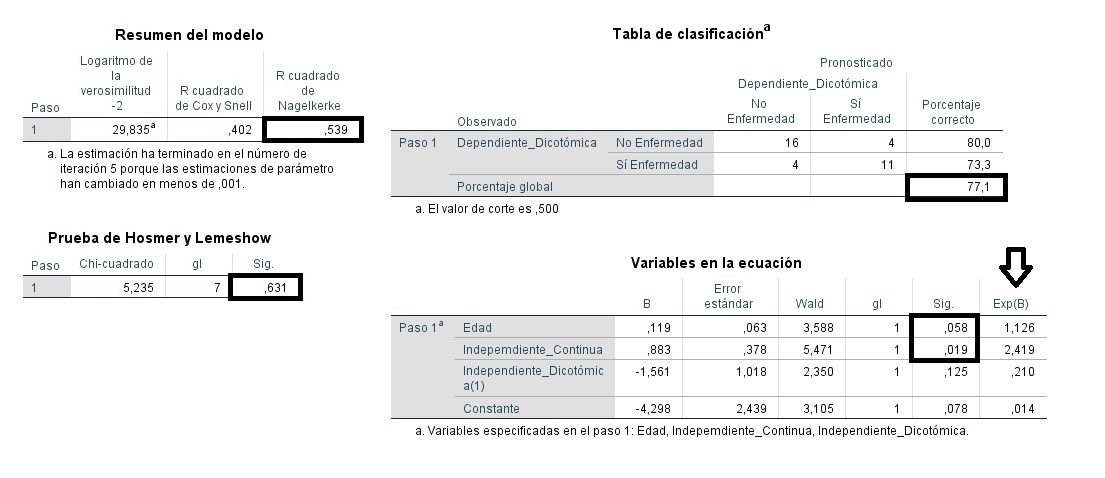
Con la prueba de Hosmer-Lemeshow, el modelo logístico se considera potable (0,631>0,05), y explica el 53,9% de la variabilidad a partir del valor de R cuadrado de Nagelkerke (algunos autores consideran una especie de media entre los 2 R cuadrado de la tabla, quizá mejor Nagelkerke por ser tipificado y entre 0 y 1), si tenemos en cuenta las 3 variables predictoras del ejemplo planteado. El p-valor asociado a la variable explicativa ‘EDAD’ es estadísticamente significativo (0,058<0,1) sólo al 10% (a veces el alfa de 0,1 es el nivel de significación fijado para la investigación, si tenemos una muestra escasa, o si la variable se considera relevante en el estudio). El valor del parámetro Exp(B), también conocido como ODDS, es de 1,126 (>0) luego inclina la probabilidad de ocurrencia hacia el valor definido como 1 para la variable dependiente de respuesta dicotómica. El p-valor asociado a la variable explicativa ‘Independiente_Continua’ es estadísticamente significativo al 5% (0,019<0,05) , y el valor del parámetro de 2,419 (>0) inclina la probabilidad de ocurrencia también hacia el valor definido como 1 para la variable dependiente. La variable ‘Independiente_Dicotómica’ , por el contrario, no resulta estadísticamente significativa de cara a predecir el modelo de regresión logística binaria (0,125>0,05), por lo que se repite la regresión, obviando la misma.
*Si bien en teoría coeficientes como el de Nagelkerke pueden alcanzar valores elevados, resulta difícil en los ajustes que incluso puedan superar valores del 0,3 (30%), puesto que no son estrictamente medidas de asociación/relación sino de probabilidad, que nos orientan sobre la ganancia que nos produce el modelo sobre situaciones en las que no hay modelo.
Siempre se debe ejecutar un análisis estadístico de regresión múltiple (tanto multivariante como de regresión logística), con todas las covariables que se considere pueden ser importantes de cara a predecir el modelo, para posteriormente, y en el caso de que todas las VARIABLES explicativas no resulten estadísticamente significativas, llevar a cabo una nueva regresión, eliminando aquellas variables independientes que no resultaron significativas en el anterior ajuste:

Ambas variables resultan estadísticamente significativas para la regresión al 0,1 de nivel de significación.
Para un mismo valor de la variable ‘Independiente_Continua’, el que la ‘Edad’ aumente un año, aumenta un 15,1% el Odds (probabilidad de ocurrencia) de la ‘Enfermedad’ (valor 1 de la variable de respuesta dicotómica), al encontrarse 1,15 entre 1 y 2, se habla de un aumento del 15,1% (equiparar tanto por uno a tanto por ciento).
Para un mismo valor de la variable ‘Edad’, el que la aumente una unidad la variable ‘Independiente_Continua’, hace que aumente 2,56 veces el Odds (probabilidad de ocurrencia) de la ‘Enfermedad’, es decir, valores mayores de 2 se expresan como esa tasa de aumento en concreto.
Para valores entre 0 y 1, se produce una reducción de 1 menos ese valor, expresado en %.
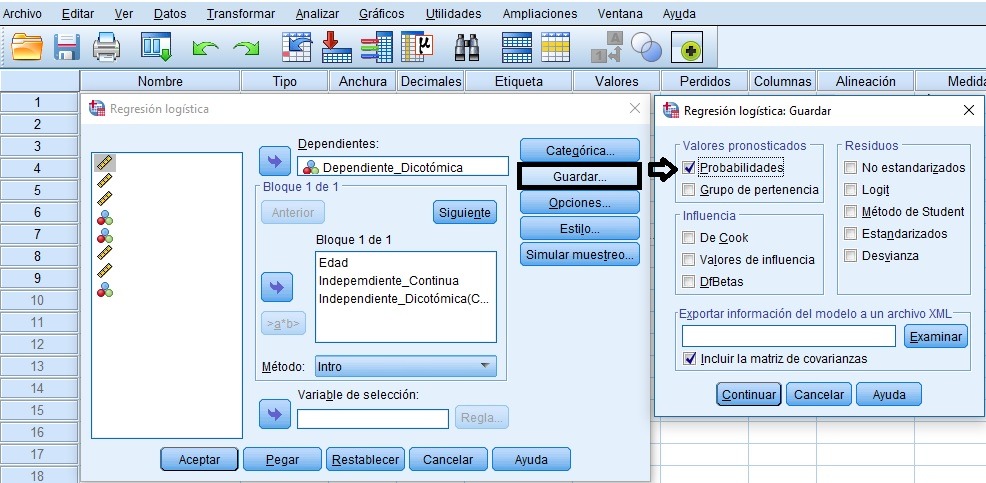
¿Cómo estimar la probabilidad de ocurrencia de la dependiente dicotómica a partir de variables explicativas, dando valores a las mismas?:

Pronóstico de probabilidad de los casos/individuos:
estamatica@gmail.com