

Regresión Logística Binaria con el software Minitab
Se trata de obtener las probabilidades de ocurrencia de una variable de respuesta dicotómica, en función de los predictores, que pueden ser numéricos, nominales de tipo también dicotómico y categóricas cuyas categorías hay que recodificar en dicotómicas, mediante variables dummy, por ejemplo de una variable de 3 categorías generamos 3 variables dummies, en la que damos valor 1 si pertenece a la categoría en concreto, 0 para el resto. Este tipo de variables dependientes se consideran del tipo Binomial (éxito contra fracaso como convención), pueden ser del tipo de DEFECTUOSO versus NO DEFECTUOSO en un proceso de fabricación de piezas industriales, ENFERMO versus NO ENFERMO en Bioestadística, FUNCIONA una campaña de Marketing Digital o NO FUNCIONA, etc.
El Test de Hosmer-Lemeshow es la prueba más fiable en cuanto a bondad del ajuste, si resulta significativa, esto es, su p-valor asociado mayor que 0,05, se puede concluir con que tiene sentido el realizar un ajuste de regresión logística, siempre que el R cuadrado se considere lo suficientemente importante.
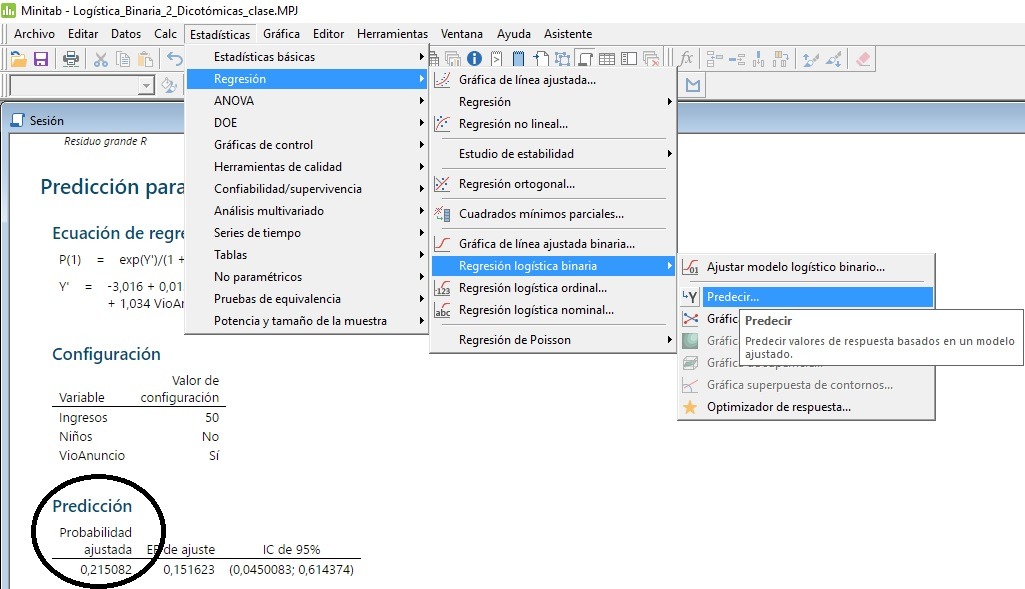
Predicción de la probabilidad de ocurrencia de la variable dependiente en Minitab, a partir de valores de configuración estimados/medidos por el usuario en un momento dado.
Regresión Logística con variables independientes categóricas recodificadas en dummies dicotómicas
La manera de conseguir que el Minitab realice la regresión logística binaria con variables dummies, esto es, recodificar una explicativa categórica de más de 2 categorías, en una dicotómica del tipo dummy (0 y 1), como se contempla en la captura de pantalla, en la que la variable ‘NIVEL’ tiene 3 valores (alto, medio, bajo), se recodifica en 2 variables nuevas que se crean, ‘ALTO’ y ‘MEDIO’, de forma que si el caso/registro toma el valor ‘ALTO’, se le da el valor 1 a la primera y 0 para el resto, si el caso adquiere valor ‘MEDIO’ sería 0 y 1, y si el caso es BAJO serían 2 ceros (0,0). La interpretación de las relaciones de las probabilidades (odd ratio en Bioestadística) recaerían sobre la variable ‘BAJO’, que es la que se omite:

**IMPORTANTE: se puede desactivar la casilla de 'Incluir el término constante en el modelo'

Entrar a formar parte del modelo de regresión logística aquellas variables cuyo p-valor asociado sea menor que 0,05 (5%) ó 0,1 (10%), en función del nivel de significación alfa decidido para la investigación.
Interpretación de las Odds Ratio: La relación de probabilidades como predictores continuos indica que a partir de la medición, existe aproximadamente un aumento del 49,82% veces más probable de resultar defectuoso, mientras que la variable % representa una disminución del (100-83,61)%. Las dummies no se interpretan al no ser estadísticamente significativas en la tabla de coeficientes (p-valor>0,05):

Todas las pruebas de bondad de ajuste son mayores que el nivel de significación de 0,05, por lo que no se puede rechazar el que se pueda llevar a cabo este modelo de regresión. La prueba de Hosmer-Lemeshow no resulta estadísticamente significativa, por lo que se considera conveniente el hacer este tipo de ajuste. El valor de R2 indica que el modelo explica aproximadamente el 10,12% de la variabilidad en la variable respuesta, por lo que no se considera un modelo excesivamente potable:

Predicción de los valores con la regresión logística

Predecir los valores de la probabilidad de ocurrencia de la variable dependiente, a partir de valores que proporciona el usuario para las variables explicativas numéricas (predictores continuos), y las dicotómicas o dummies (predictores categóricos) del ajuste:

La predicción para valores de probabilidad de defectuoso es del 70,19% (0,7019), una vez se ejecuta el modelo de predicción con los valores de los predictores continuos y dicotómicos del ejemplo.