

Tipos de Regresión en Estadística
Dentro del análisis de correlación y regresión, se define un modelo de regresión como un procedimiento que puede ser usado siempre que una variable dependiente de respuesta cuantitativa pueda ser expresada como función de otra variable también cuantitativa, o de una combinación de variables independientes (cuantitativas y/o dicotómicas). El primer caso se conoce como Análisis de Regresión Lineal Simple (MRLS o RLS) y el segundo como Análisis de Regresión Múltiple (GLM).
La manera en la que se relacionan la variable explicativa y la variable explicada puede ser muy diversa. Pueden darse relaciones lineales (directas o inversas), exponenciales, potenciales, logarítmicas, polinómicas, etc. Estas 2 últimas regresiones, son muy comunes en Econometría.
Índice del Artículo
Regresión Lineal Simple
Además de que lo que se pretende es encontrar un modelo de ajuste para predecir la relación lineal existente entre la variable dependiente Y, y la independiente X, conviene estudiar los índices para cuantificar dicha relación lineal (R cuadrado o coeficiente de determinación de bondad del ajuste), además del cálculo e interpretación de los coeficientes de la regresión (término independiente Bo, y pendiente de la recta B1).
El método de ajustar una recta de regresión se le conoce como ajuste por mínimos cuadrados, ya
que el objetivo es encontrar los valores del término independiente (intercept) y de la pendiente que minimizan el error al cuadrado.
En el análisis de regresión simple, el coeficiente de regresión principal es el B1, conocido como pendiente de la recta, representa el incremento o decremento (variación) que se produce en la estimación de la variable dependiente, cuando la independiente (X) se incrementa en una unidad. El término constante de la recta de regresión, Bo, señala el punto en el que ésta corta al eje de ordenadas (0,0), por lo que es conocido como ordenada en el origen. Es decir, refleja el valor estimado de la variable explica Y, cuando la explicativa X es igual a 0.
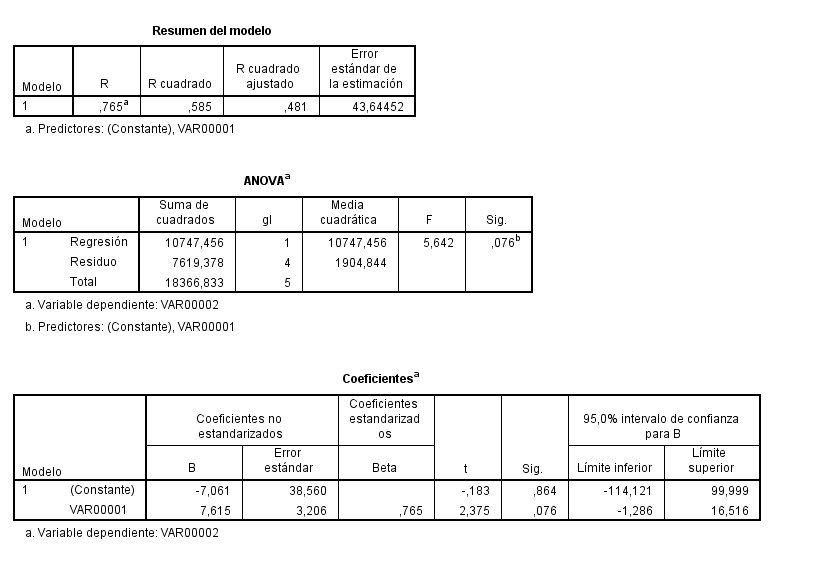 El modelo de regresión lineal simple explica el 58,5% de la variabilidad de la variable dependiente de respuesta, a partir del coeficiente de determinación R cuadrado (en la regresión simple se mira el R cuadrado, en la regresión múltiple, en cuanto intervengan 2 o más variables explicativas, se mira en R cuadrado ajustado). La representación gráfica del modelo de regresión lineal simple es el gráfico de dispersión. Los residuos o errores se corresponden con la diferencia entre cada valor real de la nube de puntos, y el ajustado ideal de la recta de regresión.
El modelo de regresión lineal simple explica el 58,5% de la variabilidad de la variable dependiente de respuesta, a partir del coeficiente de determinación R cuadrado (en la regresión simple se mira el R cuadrado, en la regresión múltiple, en cuanto intervengan 2 o más variables explicativas, se mira en R cuadrado ajustado). La representación gráfica del modelo de regresión lineal simple es el gráfico de dispersión. Los residuos o errores se corresponden con la diferencia entre cada valor real de la nube de puntos, y el ajustado ideal de la recta de regresión.
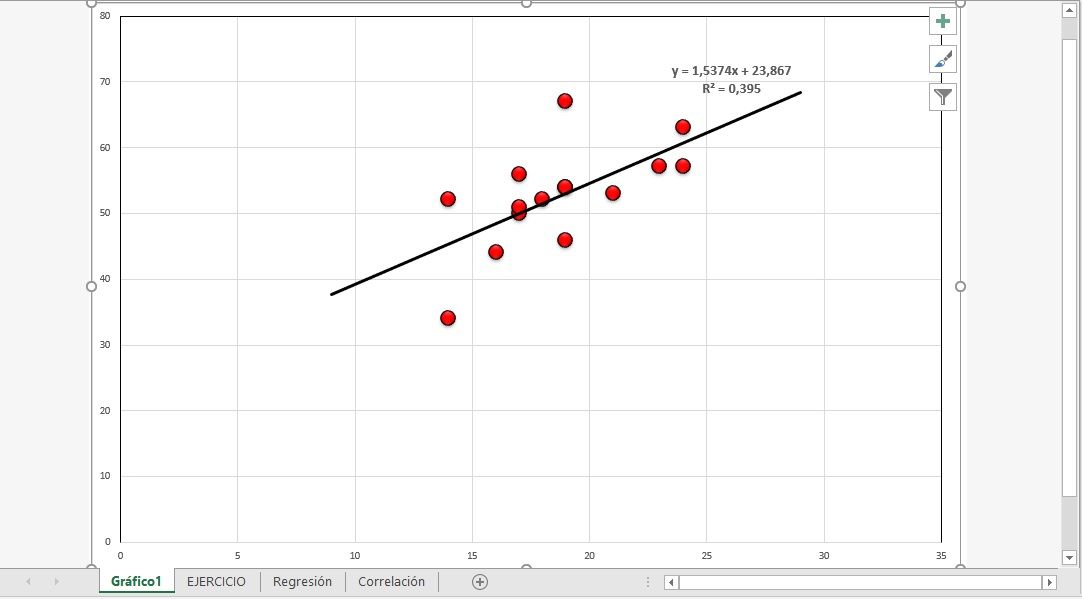
Al inspeccionar el gráfico de dispersión (representación gráfica de la nube de puntos), se aprecia una tendencia lineal y una relación directa entre las variables en juego. A medida que la variable independiente puntúa más alto (X), se observan valores mayores en la variable de respuesta (Y).
Regresión Curvilínea
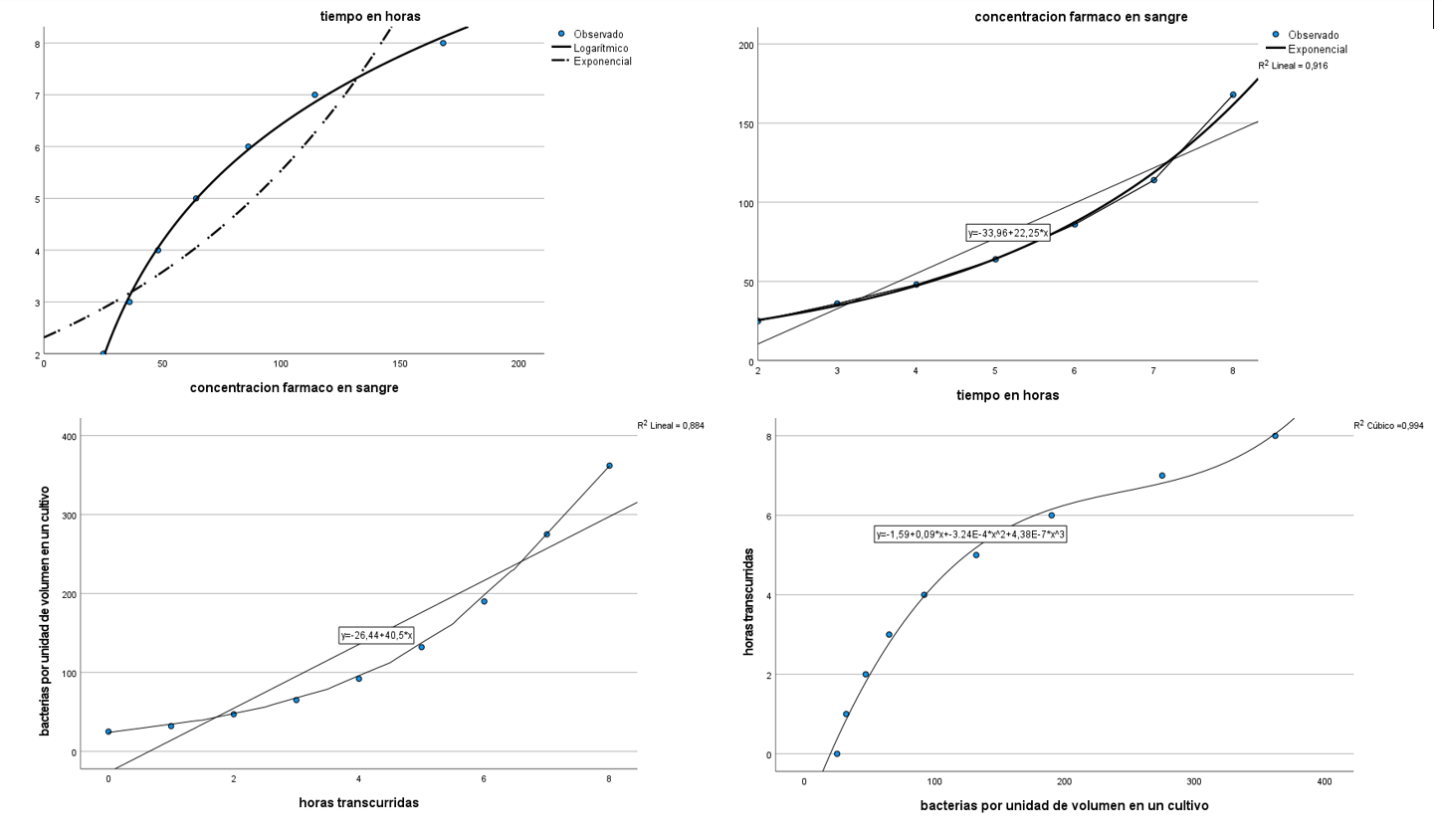
Regresión curvilínea: cuando la relación no es lineal
En muchos contextos científicos, como la farmacocinética o el crecimiento microbiano, las relaciones entre variables no siguen un patrón lineal. En estos casos, la regresión curvilínea permite ajustar modelos más realistas que capturan mejor la naturaleza de los datos.
En la imagen se comparan distintos tipos de regresión:
Modelos logarítmicos, exponenciales y polinómicos se ajustan a los datos observados.
Se muestran coeficientes de determinación (R²) que evidencian un mejor ajuste de los modelos curvilíneos frente al modelo lineal, especialmente en el caso cúbico (R² = 0,994).
Las fórmulas matemáticas de los modelos permiten predecir el comportamiento de las variables con mayor precisión.
Ventajas de la regresión curvilínea:
Mayor precisión en el ajuste.
Representación adecuada de fenómenos no lineales.
Mejora en la capacidad predictiva del modelo.
Cuando los datos no siguen una línea recta, aplicar modelos de regresión curvilínea permite describir y predecir fenómenos con mayor exactitud. Elegir el modelo adecuado es esencial para un análisis estadístico riguroso y efectivo.
Regresión Múltiple
Se trata de detectar si varias covariables independientes afectan significativamente a la variable de respuesta dependiente y el impacto de esa relación, así como si efectivamente se puede elaborar un modelo predictivo puede resultar potente de cara al ajuste por regresión. Se deben cumplir los supuestos de partida de independencia de los errores y no multicolinealidad. La representación gráfica del ajuste es el hiperplano de regresión.


El coeficiente de determinación ajustado del modelo es muy bueno, la regresión explica más del 97% de la variabilidad de la variable dependiente, lo que también corrobora el p-valor de la Tabla Anova estadísticamente significativo. La variable X1 y X2 resultan estadísticamente significativas para predecir el modelo. Se trata de intuitivamente probar diferentes combinaciones de variables hasta encontrar el ajuste que mejor regresa la variable de respuesta. En este ejemplo las variables X1 y X2 parecen ser las mejores candidatas al modelo definitivo, luego repetimos las regresión con estas 2 variables explicativas:

Regresión Logística Binaria
Ahora la variable dependiente es la probabilidad de ocurrencia de un evento dicotómico, muy común en Bioestadística, como suele ser la probabilidad de EXITUS, de reintervención quirúrgica, de cura de una enfermedad, de utilidad de un fármaco, etc.
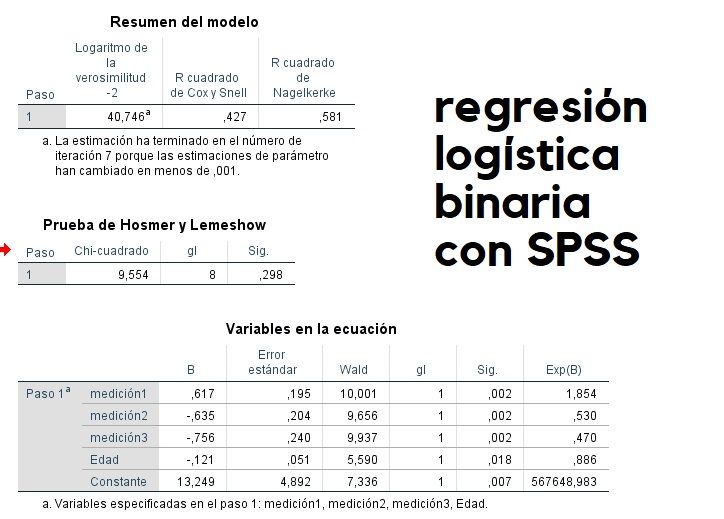
A través del R cuadrado de Nagelkerke o de la no significatividad estadística de la prueba de Hosmer-Lemeshow, se considera conveniente el realizar una regresión logística, donde las 4 variables del modelo resultan estadísticamente significativas, por lo que se pueden interpretar las ODDS RATIO:

* captura de pantalla del Departamento de Estadística de Medicina de la Universidad de Valencia
Regresión Logística Multinomial

En este caso se trata de detectar la influencia de los predictores continuos o dicotómicos en la probabilidad de ocurrencia de la variable de respuesta de más de 2 categorías.

Regresión de COX
El Análisis de Supervivencia se define como conjunto de técnicas estadísticas para estudiar la variable dependiente tiempo hasta que ocurre un evento dicotómico (censurado), y su dependencia de otras covariables predictoras, continuas y categóricas dicotómicas. La idea es hacer un modelo de esta variable de respuesta, que se considera potable a partir de la significatividad de la prueba omnibus de la Chi-cuadrado, en el que a partir de los predictores estadísticamente significativos, poder interpretar los valores de las Hazard Ratio (mayores o menores de 1), como indicadores del aumento o disminución de riesgo del evento de interés dicotómico (exitus, reintervención quirúrgica, enfermedad, accidente, etc). En el caso de predictores categóricos con más de 2 categorías, se recodifica en variables dummies (por ejemplo 3 categoría se recodifica en 2 variables ficticias, 4 en 3, y así sucesivamente).
Superficies de Respuesta (MINITAB)

Cuando se trata de contrastar también si las interacciones son importantes de cara a la predicción, en un diseño factorial para detectar las relaciones causa-efecto, o lo que es lo mismo, testear si resultan estadísticamente significativos para el modelo de superficie de respuesta, aquellos efectos principales e interacciones cuyo p-valor asociado sea menor de 0,05, probando hasta el ajuste final con solo las variables y las interacciones significativas.