


Tutorial de Statgraphics
Índice del Artículo
Análisis Estadístico con Statgraphics

El paquete estadístico Statgraphics es un software profesional especialmente diseñado para facilitar el análisis estadístico de datos de forma avanzada, ya sea en el aspecto Descriptivo de los mismos, técnicas Multivariantes: Anovas, Factorial, Conglomerados, Correspondencias, Discriminante; así como Intervalos de Confianza, Contrastes de Hipótesis Paramétricos (T de Student, Levene de Homocedasticidad) y No Paramétricos (U de Mann-Whitney, Wilcoxon, Kruskal-Wallis), técnicas de Marketing, control de calidad, etc.
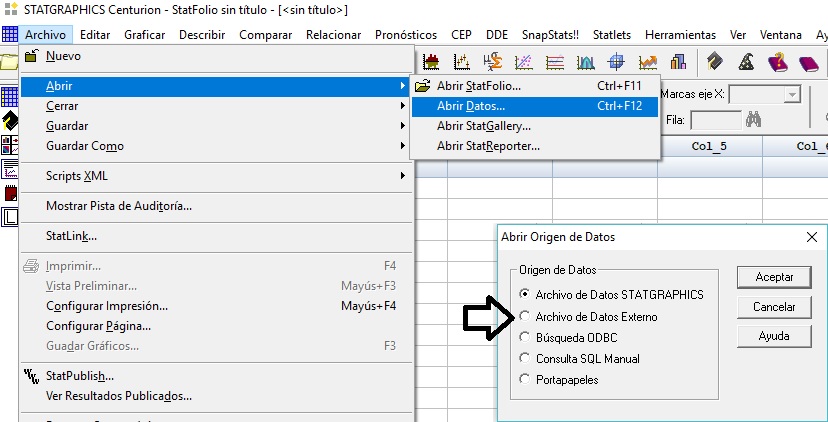
Generar variables a partir de otras
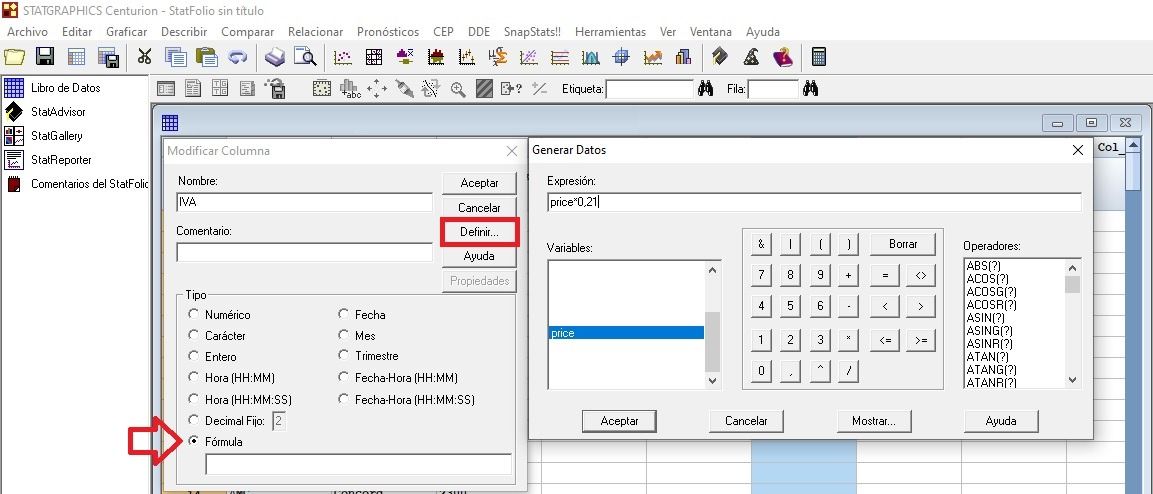
Modificar columna>>Fórmula>>Definir…
Recodificar variable en intervalos
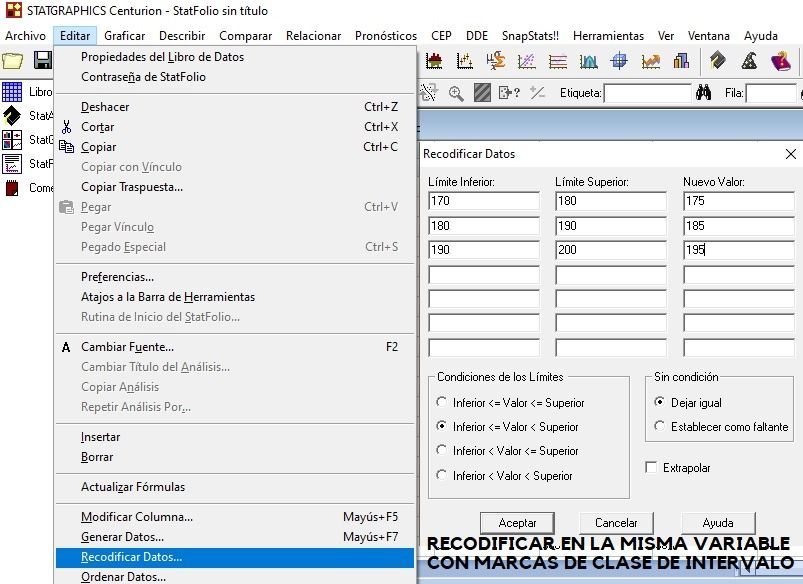
Recodificar en la misma variable, en intervalos a partir de la marca de clase de los mismos, para generar por ejemplo, una tabla de frecuencias.

Estadísticos Descriptivos con Opciones de Ventana
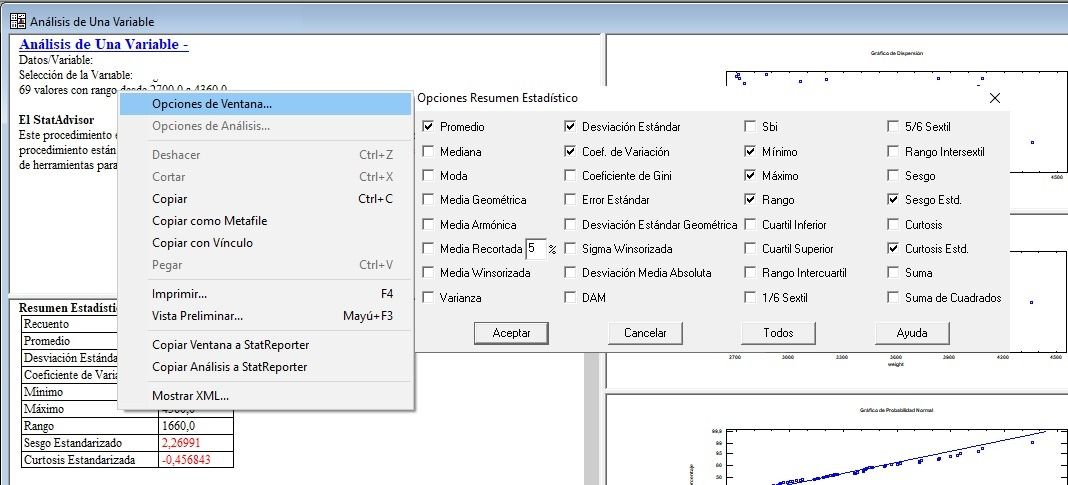
Clic con botón derecho sobre la tabla de Resumen Estadístico del menú Describir: Datos Numéricos: Análisis de Una Variable, y aparece el menú contextual donde seleccionar los estadísticos descriptivos a utilizar en el análisis descriptivo de las variables de nuestra base de datos.
Tabulación Cruzada
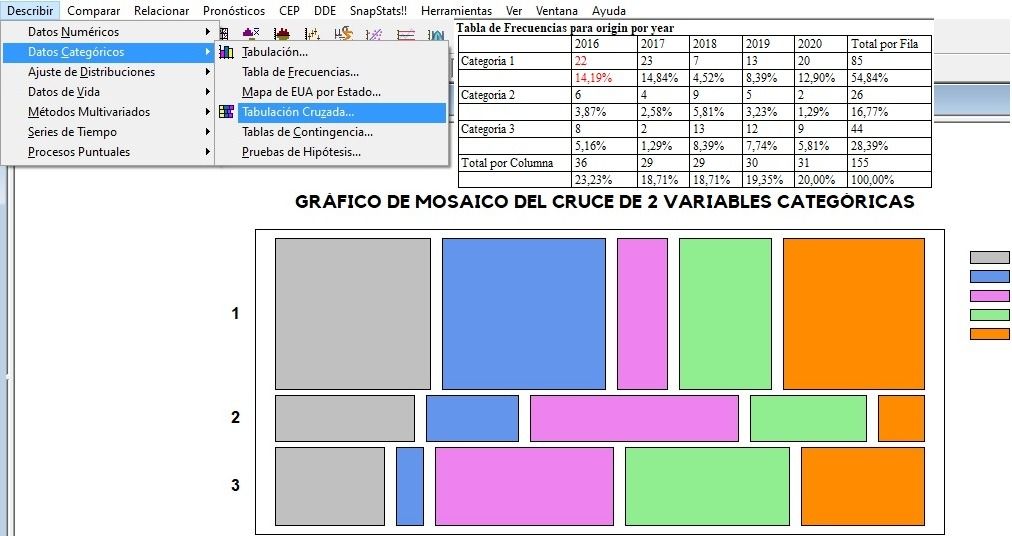
Tabulación cruzada de variables categóricas o de números enteros con no demasiados números a repartir las frecuencias. Representación gráfica con mosaico de la distribución de las categorías de los datos.
Análisis de Correlaciones entre variables numéricas (continuas)
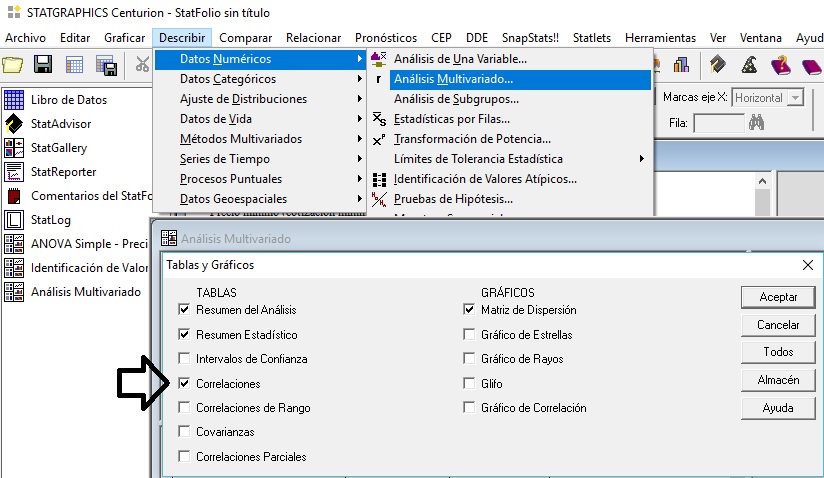
Si el p-valor asociado al cruce de las 2 variables es menor que 0,05, se concluye con que existe relación/asociación/dependencia lineal entre las 2 variables del cruce. El asterisco (*) también denota que el contraste de independencia es estadísticamente significativo. El grado de la relación viene dado por el coeficiente de correlación lineal de Pearson, entre [-1;1].
Histograma con curva normal
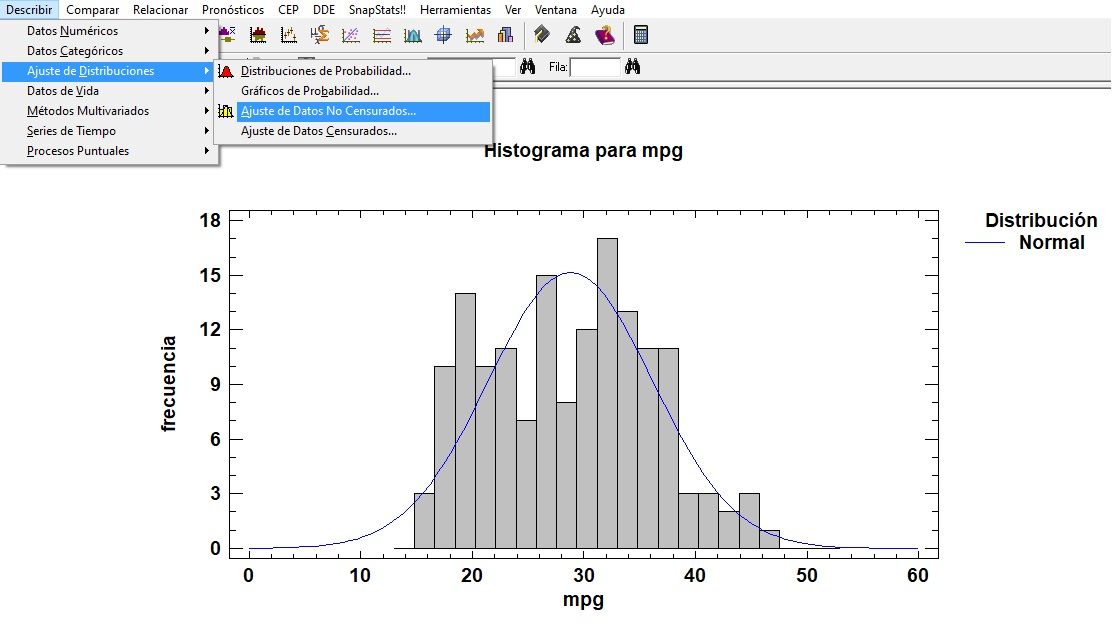
Tablas de Distribuciones
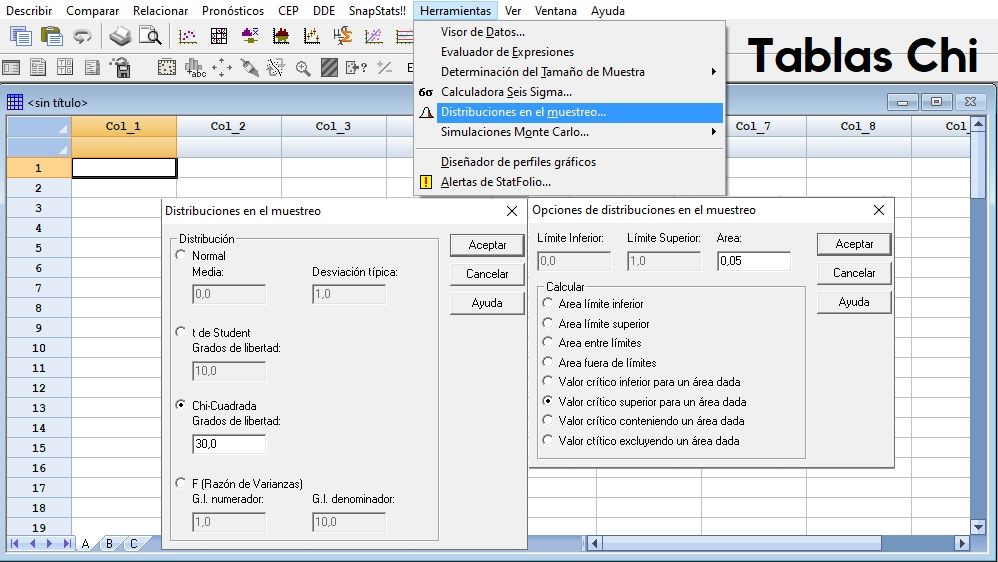
A partir del submenú ‘Distribuciones de muestreo’, se pueden buscar los valores críticos en Tablas, en el menú ‘Herramientas’, como ejemplo la Chi-cuadrado de 30 grados de libertad, para el valor crítico superior a un área (nivel de significación) de 0,05 (5%). Se pueden encontrar los valores exactos de la Normal, T de Student, Chi-cuadrado y F de Fisher-Snedecor, sin necesidad de tablas en papel, además de su representación gráfica con los propios valores críticos reflejados.
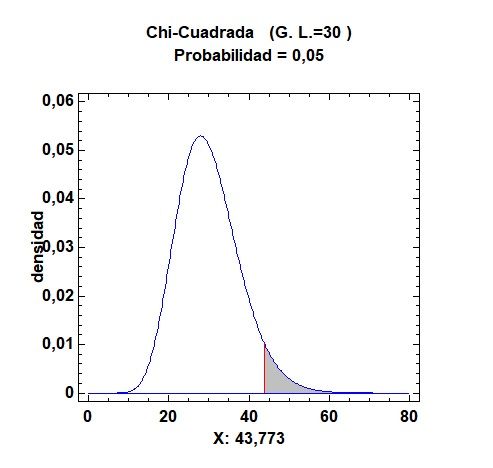
Distribución Normal
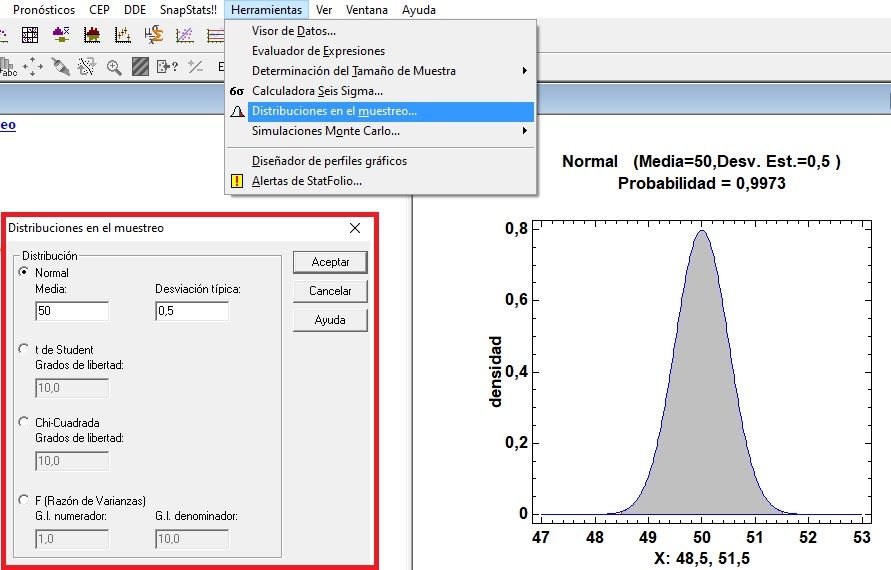
Distribución normal con valores de probabilidad dentro del área de la curva, o lo que es lo mismo, cual el el % de estar comprendido entre 2 valores a partir de una distribución normal conocida.
Ajuste de Distribuciones de Probabilidad
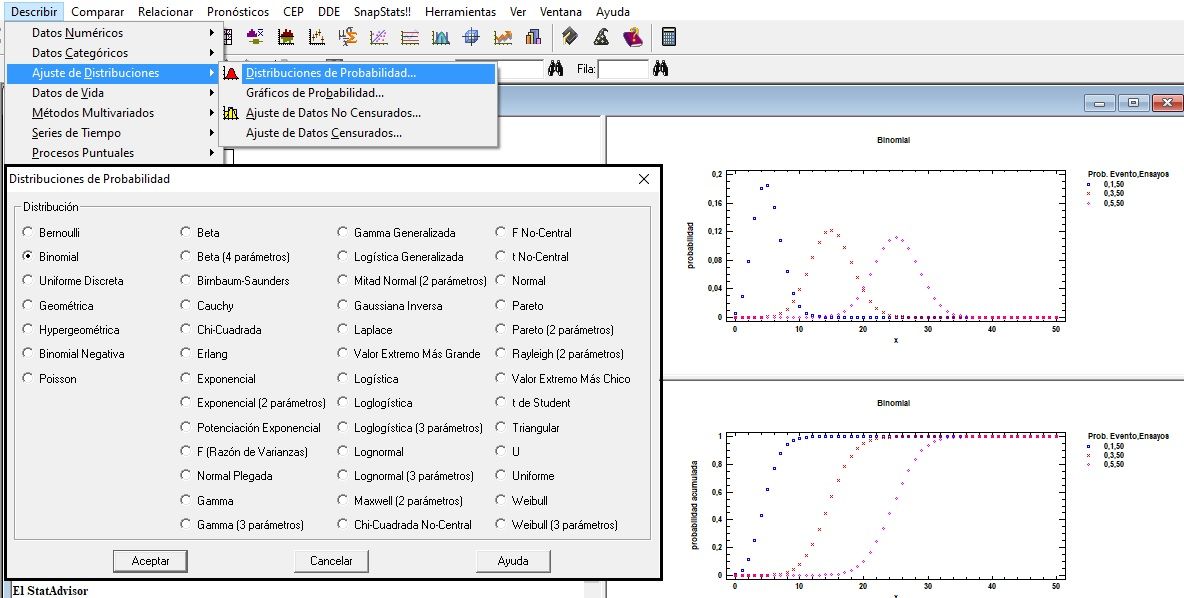
Con la opción de ‘Ajustes de distribuciones de probabilidad’, se pueden comparar, por ejemplo, hasta 5 distribuciones Binomiales (número de éxitos en n ensayos independientes). Por defecto el software ajusta la distribución Normal.
Tamaño Muestral
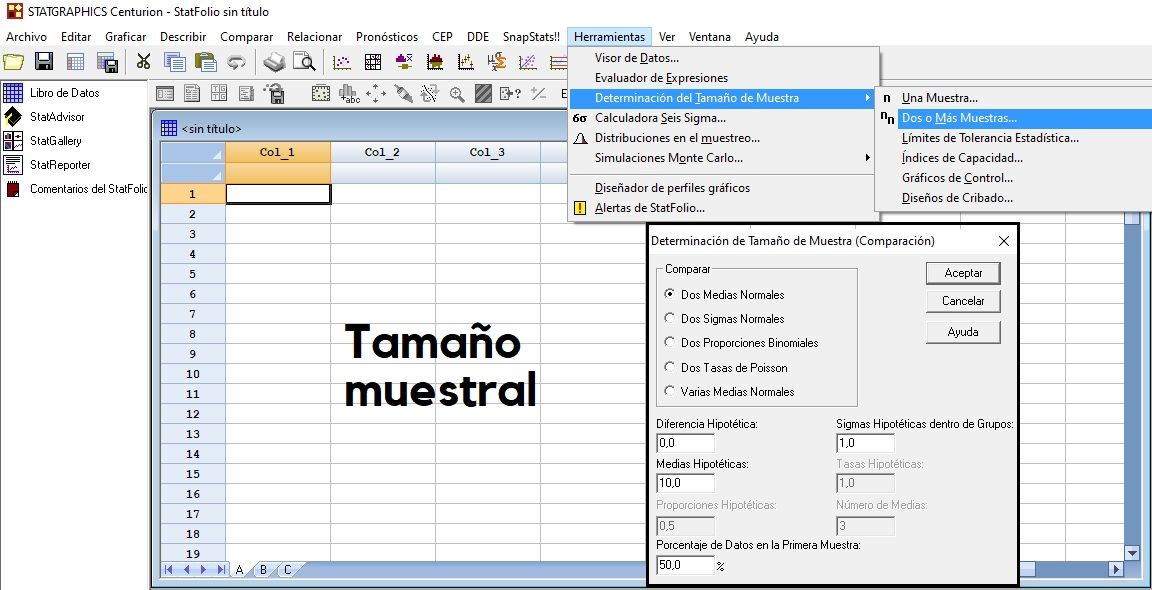
Contraste de Proporciones (Binomial)
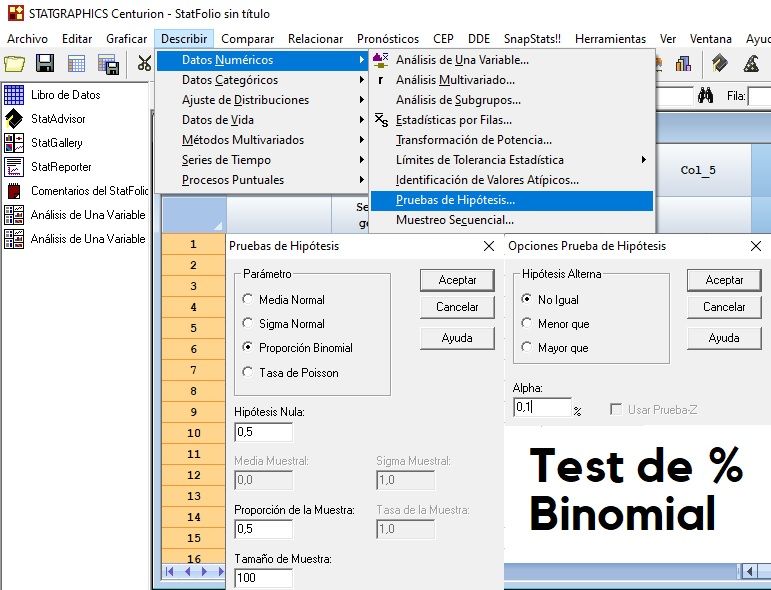
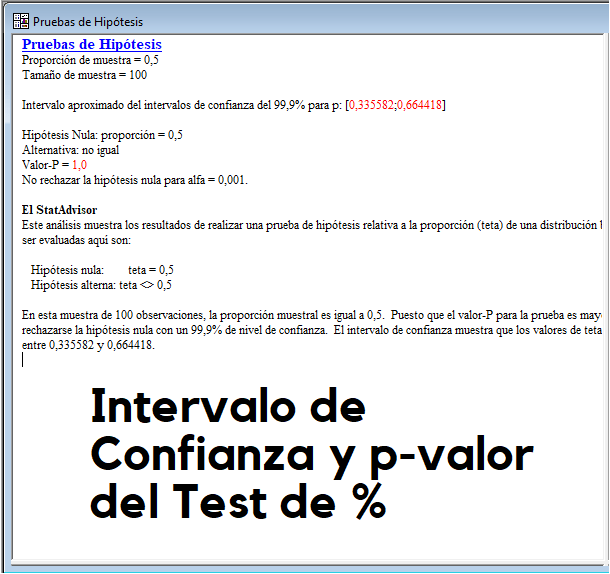
Gráfico de Dispersión
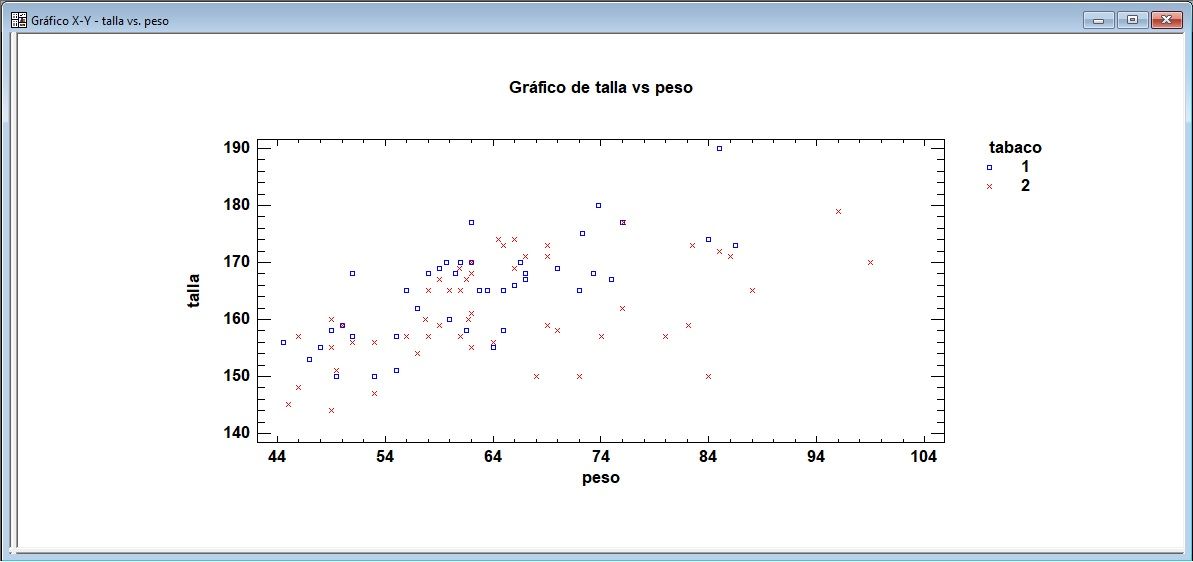
Gráfico de Dispersion X-Y en Statgraphics, menú contextual botón derecho sobre el gráfico, ‘Opciones de ventana’, y variable para segmentar en ‘Código de puntos’.
Regresión Múltiple (GLM de Econometría)

Las variables independientes cuyo p-valor asociado sea menor que 0,05 son las que entrar a formar parte del modelo de predicción de la variable dependiente. El R2 determina la bondad del ajuste o proporción de variabilidad explicada por el modelo de regresión múltiple o GLM. Previamente a la regresión se comprueban los supuestos de partida o hipótesis subyacentes del modelo: linealidad (correlación de la dependiente con las independientes), independencia de los errores, y no multicolinealidad entre las variables predictoras.
Supuesto de Normalidad

En la práctica, Normalidad Multivariante suele implicar Normalidad Univariante. Si en el contraste de Shapiro- Wilk (muestras menores de 50) o en el de Kolmogorov-Smirnov con la corrección de Lilliefors (mayores de 50) alguna variable no cumple el supuesto de Normalidad (p-valor asociado<0,05), se concluye con que no se cumplirá la Normalidad Multivariante, siempre como norma general.
Comparativa de medias poblacionales disponiendo de medias y varianzas muestrales
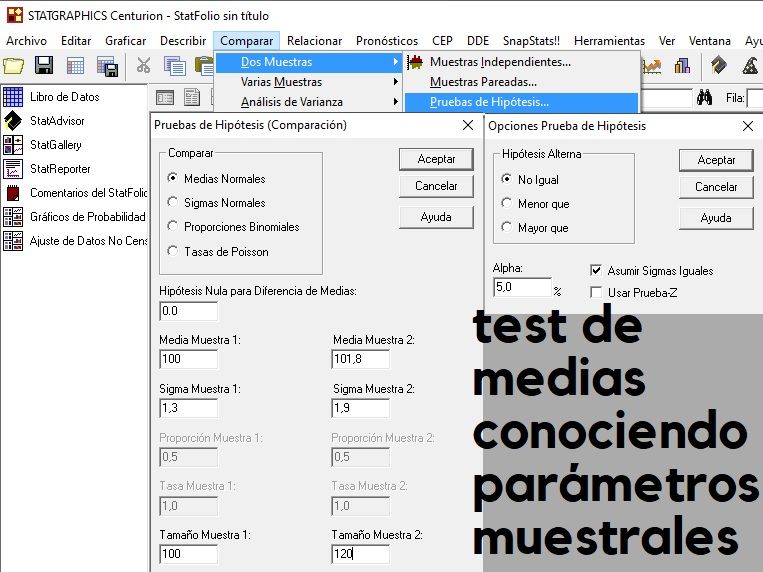
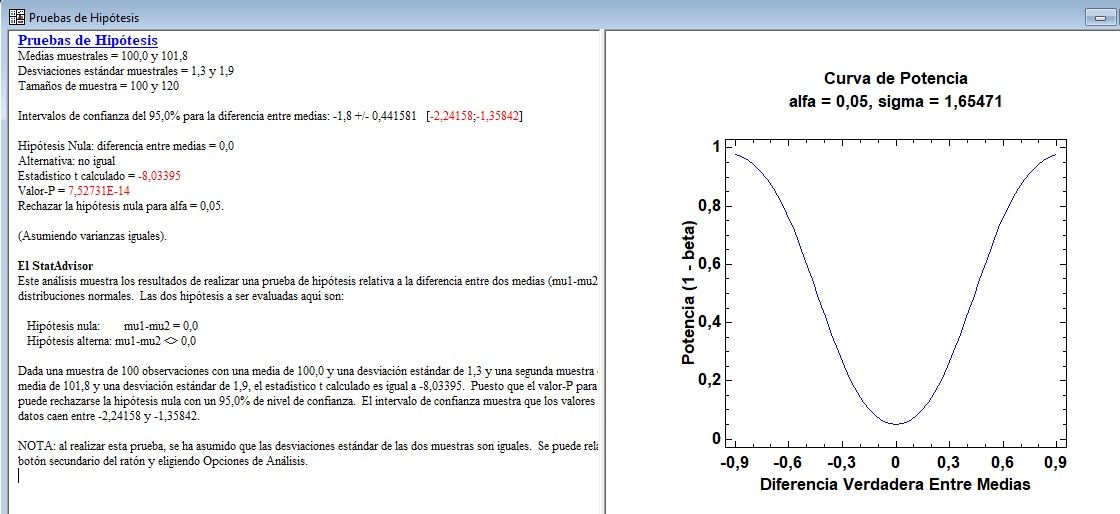
T de Student de muestras independientes con variable filtro
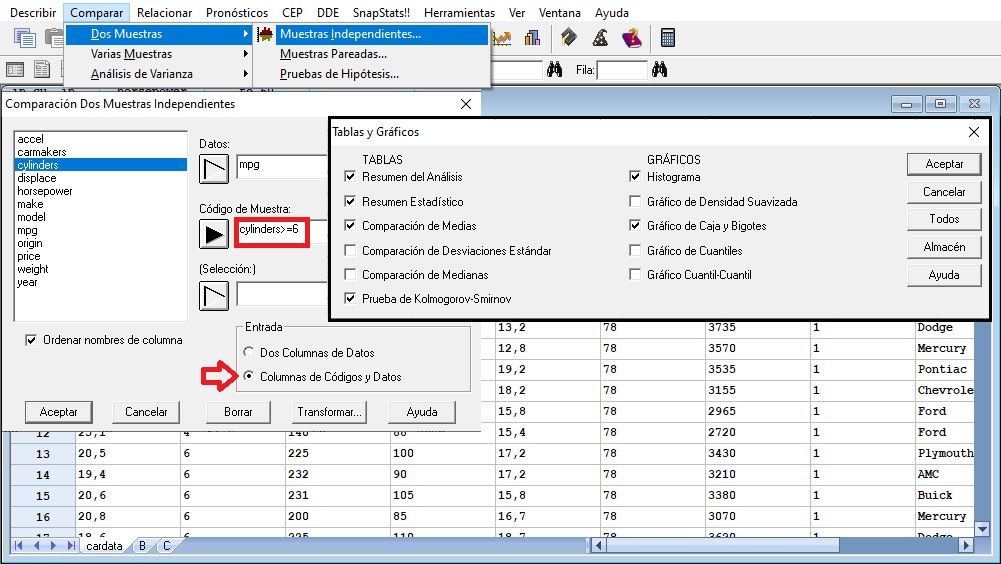
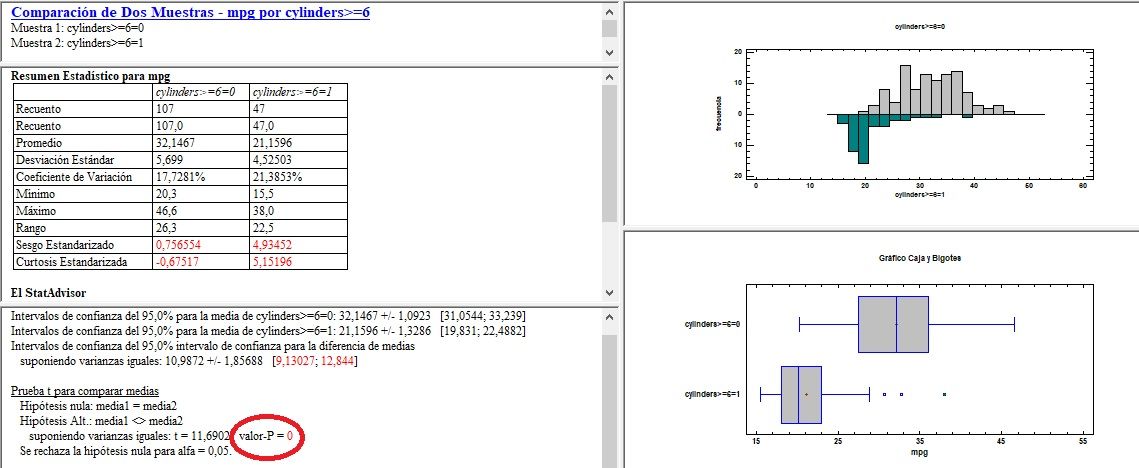
T de Student con variable independiente (la que hace los 2 grupos para comparar las medias), segmentada en dicotómica de manera automática. Se aprecian diferencias estadísticamente significativas entre ambos grupos, pues el p-valor asociado al estadístico del contraste, resulta estadísticamente significativo (p<0,05):
ANOVA Multi

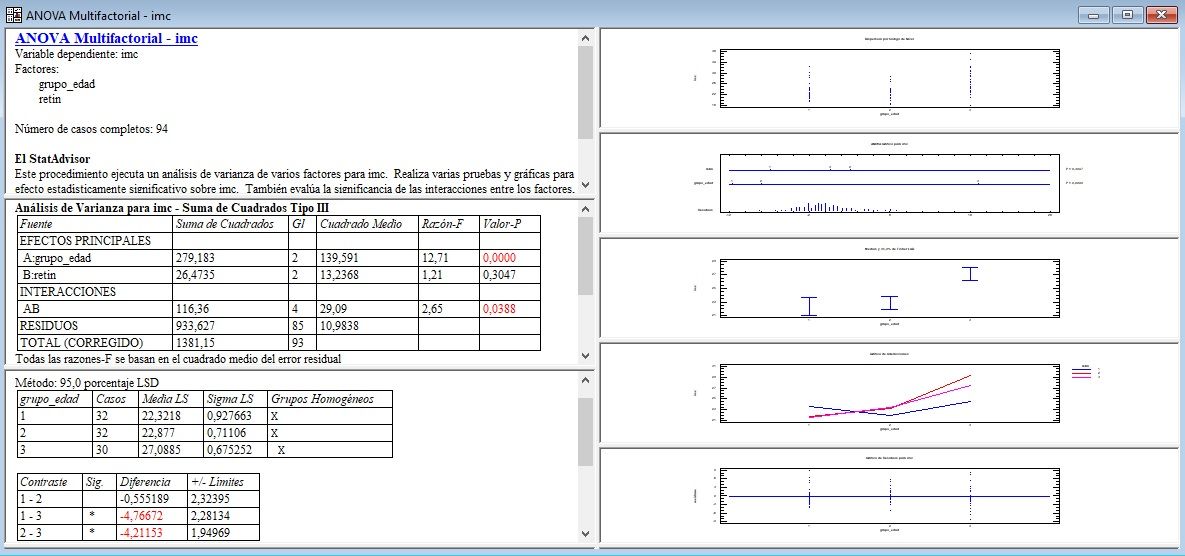
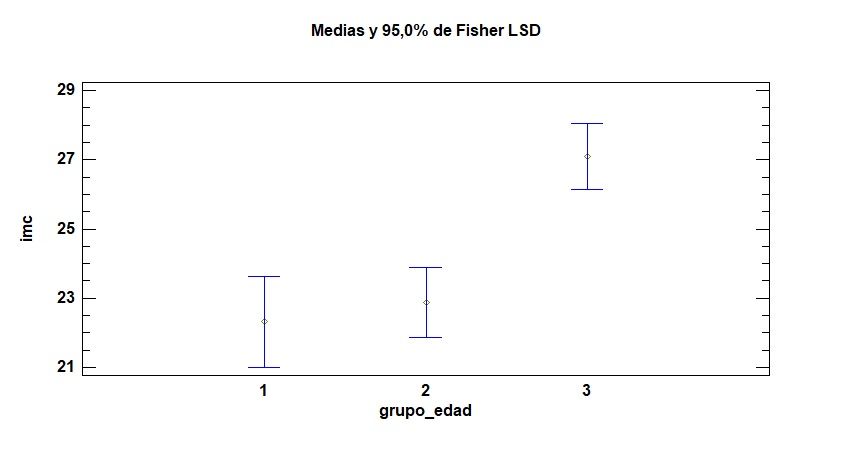
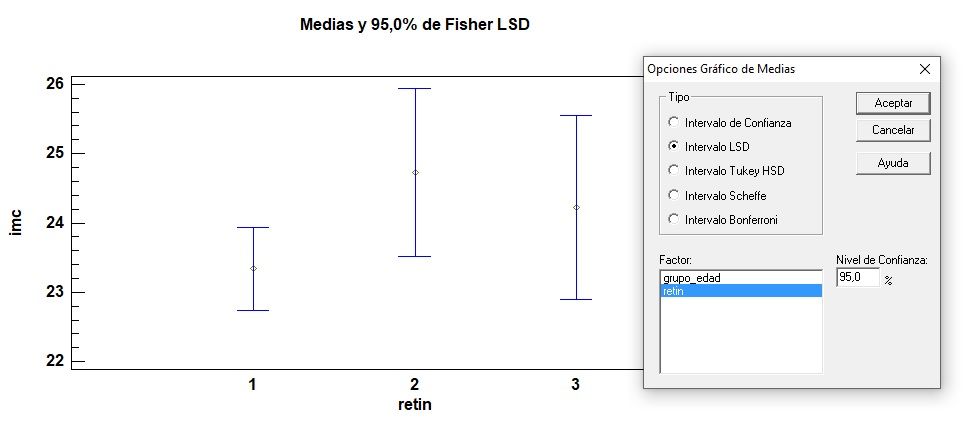
A partir de la comprobación de los supuestos de partida de Normalidad, Homocedasticidad y Aleatoriedad se trata de discernir si la media de la variable dependiente continua es la misma en los 3 grupos que conforma una de las variables independientes o primer factor, en los 2 o más grupos que forma el segundo factor (a ambos contrastes se les denomina Efectos Principales), y además si la interacción de estos 2 factores es estadísticamente significativa. Posteriormente se realizan las Pruebas POST HOC para cada uno de los factores.
Representación de residuos sobre un papel probabilístico normal
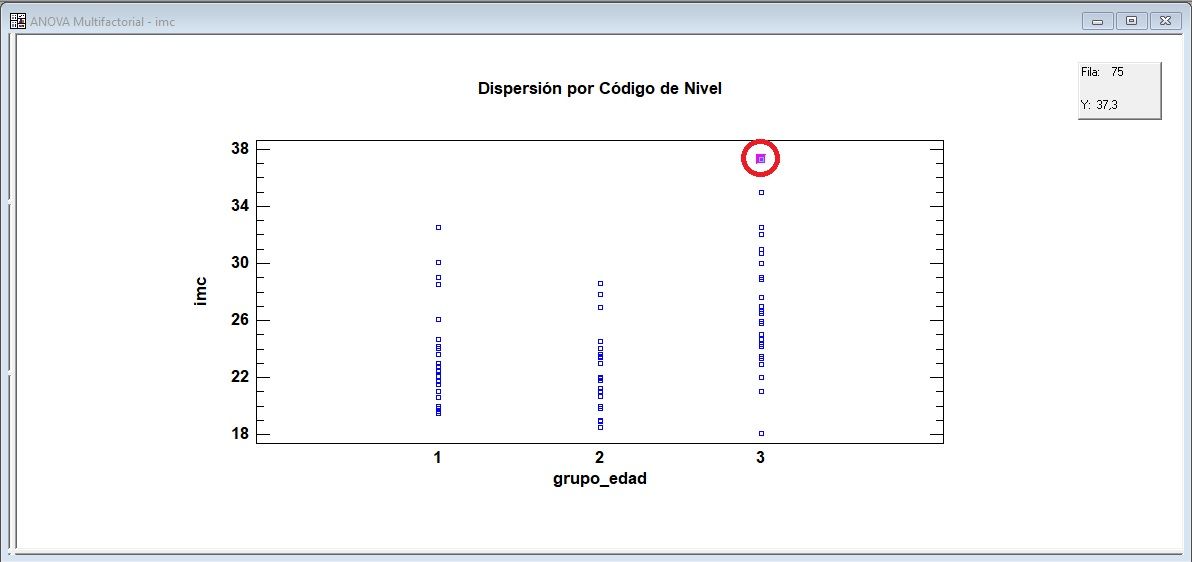
Eliminación de residuos atípicos en gráfico de normalidad de residuos, y repetición del análisis estadístico de la tabla ANOVA de 2 factores, para detectar significatividad en los efectos (factores) principales y en la interacción. Si la interacción resulta estadísticamente significativa, se conserva los factores incluso aunque no resulten significativos en el modelo final.
Análisis de Conglomerados–Clusters
El Análisis de Conglomerados o Cluster Analysis es un análisis estadístico multivariado de clasificación de registros o casos. Los elementos tienden a agruparse en en grupos homogéneos, lo que se conoce como clusters =conglomerados, en función una serie de características que pueden presentar en común (distancias). Así, los diferentes casos que presentan características similares se asignan a un mismo conglomerado y los distintos a diferentes cluster.
Análisis de Componentes Principales
Como ya sucedía en el Análsis Factorial Exploratorio, se transforman un conjunto de variables cuantitativas correlacionadas entre sí, en otro grupo de variables más reducido, Componentes Principales, que retienen gran parte de la variabilidad de los datos, minimizando la pérdida de información de las variables originales.

Lo que se trata es de reducir unas cuantas variables de tipo continuo a unos pocos componentes que expliquen una proporción de variabilidad importante (70-80%), a partir del criterio de eigenvalue de Kayser de retener aquellas componentes cuyo autovalor sea mayor que 1. En el ejemplo, las altas puntuaciones en peso de los componentes respecto del primer factor, parece denotar que se trata de asignaturas relacionadas con el ámbito de las Letras, la segunda componente parece correlacionarse con asignaturas de tipo científico. Otro criterio sería conservar aquellas componentes o factores donde el Gráfico de Sedimentación ‘hace codo’.
Análisis de Correspondencias

Con este tipo de Análisis en Statgraphics se pretende clasificar las categorías o grupos de una variable dependiente dicotómica o de 3 o más categorías a partir de las variables independientes clasificadoras, elaborando modelos de predicción a partir de las Funciones Discriminantes. El coeficiente de determinación eta cuadrado (cuadrado de la correlación canónica) de cada función discriminante expresa la proporción de variabilidad de cada variable dependiente expresada por las independientes clasificadoras. La Lambda de Wilks ofrece el poder discriminante de cada Función, proporción de varianza de las puntuaciones discriminantes no explicada por las diferencias entre los grupos. La Matriz de Clasificación de % de casos correctamente clasificados, expone la capacidad predictiva del modelo, es decir sirve para predecir el grupo (categoría) en que será clasificado un nuevo cliente.

