

Curso de SPSS en la Universidad de Málaga
Índice del Artículo
Importar base de datos de hoja de cálculo de Excel


Se empieza por recopilar la información en una base de datos que gestionamos como una hoja de cáculo de Excel, para posteriormente depurar esos datos y eliminar los outliers, que desvirtúen los resultados de nuestros análisis y test de hipótesis estadísticos.
Filtros y Buscar/Reemplazar
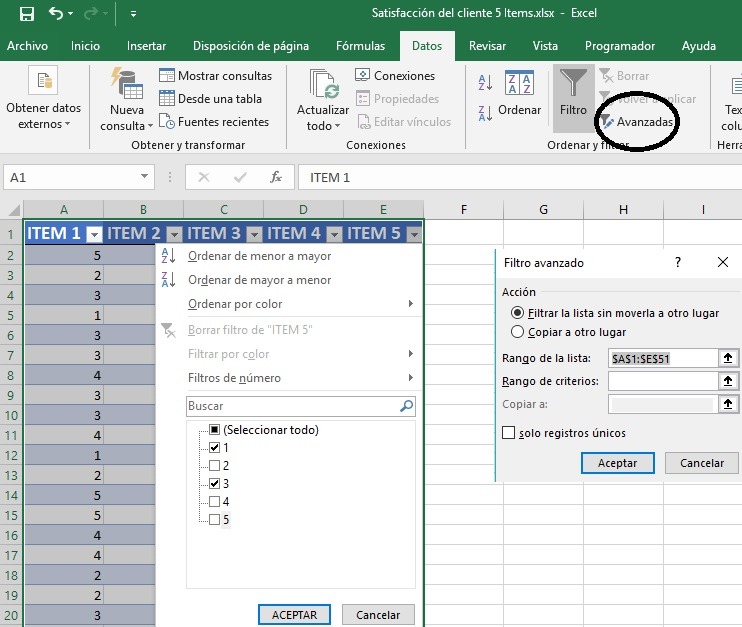

Tanto las opciones de ‘filtrado’ (avanzadas) como las de ‘Buscar’ y ‘Reemplazar’ valores de la base de datos, suelen ser muy recurrentes a la hora de depurar y ordenar los valores de nuestra base de datos de partida.
Definir las variables en la Vista de variables

Definir variables en vista de variables, sus etiquetas, tipo, escala es el primer paso a efectuar si trabajamos directamente con el SPSS, el segundo tras la importación de la base de datos de Excel, si trabajamos con una base de datos externa.
Detección de OUTLIERS

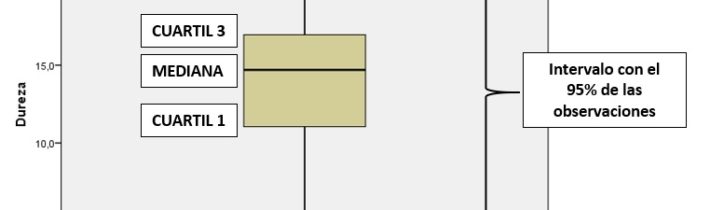
Para detectar outliers con SPSS, esto es puntos raros que desvirtúan los resultados de nuestros análisis estadísticos, se utiliza el Diagrama de caja, el que la línea central representa la Mediana (si no está en una posición central, se intuye asimetría), los lados de la caja son los cuartiles, y los extremos marcan los valores, a partir de los cuales, se encuentran los casos a eliminar de nuestro estudio, depurando de esta manera la base de datos, de manera procedente. Se consideran atípicos los valores inferiores a Q1–1.5·RIC o superiores a Q3+1.5·RIC, donde RIC es el rango intercuartílico, diferencia entre el tercer y el primer cuartil.


Ejemplo de diagrama de caja (Box-Plot), el registro/caso/fila 9 de nuestra base de datos de la muestra se considera valor atípico (outlier) y habría que depurarlo, pues puede desvirtuar los contrastes y análisis estadísticos, para posteriormente hacer inferencia, esto es, extrapolar los resultados de nuestra distribución muestral a la población. Otra forma de hacerlo, menos utilizada, es considerar como valores atípicos aquellos que se salgan del intervalo: media+/- (3*desviación típica), lo que estaría dentro de lo que se conoce como ‘Desigualdad de Chebyshev’, donde se encontrarían aproximadamente el 99,7% de nuestros datos, y siempre en el caso de que la distribución se considerara Normal (Campana de Gauss).
Estadísticos Descriptivos

Los valores de asimetría y kurtosis nos indican si la distribución de la muestra de datos puede considerarse Normal, y proceder de esta manera desde un punto de vista paramétrico, con contrastes como el de la T de Student o la Tabla ANOVA de igualdad de medias poblacionales. Los Percentiles nos pueden servir para delimitar los máximos y mínimos de los valores de nuestra distribución, en referencia a porcentajes (%). El coeficiente de variación es el cociente entra la desviación típica y la media, se puede utilizar para comparar dispersiones de distintas variables, medidas en distinta escala o no, o para definir la representatividad de la media.
Frecuencias

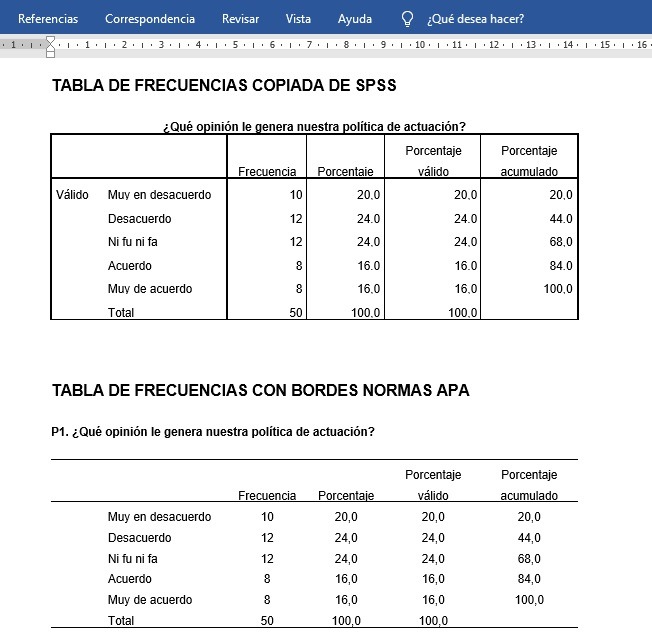
Se genera la Tabla de frecuencias absolutas y porcentuales con SPSS, a partir de la secuencia de comandos de menú de la captura de pantalla, y se puede exportar a Word para conseguir una tabla cumpliendo las normas APA. Se exporta la tabla de frecuencia del visor de resultados a una hoja de Excel (botón derecho + Copiar), donde la calidad de gráficos generados a partir de la tabla va ser mayor, es decir, se crean gráficos en Excel a partir de tablas de frecuencias, importadas del paquete estadístico SPSS. Copiamos la tabla de frecuencias en Word, directamente de SPSS, y modificamos los bordes para cumplir con las normas APA.

Histograma de frecuencias de los Items con curva Normal

Análisis de fiabilidad de los Items

Con un valor de alfa de Cronbach mayor que 0,8, queda demostrada la fiabilidad/confiabilidad de nuestra batería de items. Se puede hacer general, o pormenorizado por dimensiones o componentes subyacentes, que conforman los propios items.
Seleccionar muestra aleatoria de casos

Análisis de Correlaciones
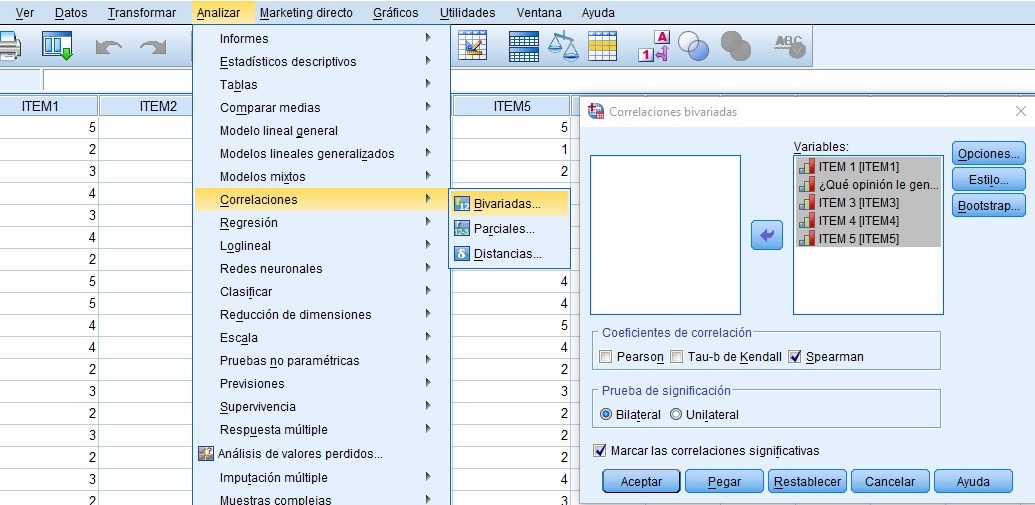

Correlaciones de Sperman para medir la relación/asociación/dependencia entre variables en escala ordinal tipo Likert, que sustituye para este tipo de cruces al coeficiente de correlación lineal de Pearson, comúnmente usado para variables de tipo continuo/numéricas. Un p-valor menor que 0,05 en el cruce entre variables, indica que el contraste de independencia es estadísticamente significativo, luego existe algo de relación entre los items, el grado de correlación (directa o inversa) viene expresado por el propio coeficiente, mayor que 0,7 en valor absoluto nos indica una relación importante.
Test de Normalidad


Tablas de visor de resultados de SPSS con p-valor de Test de Normalidad, un p-valor menor que 0,05 resulta estadísticamente significativo, se rechaza la hipótesis nula de que los datos se distribuyen normalmente. Dependiendo del tamaño muestral utilizamos el Test de Kolmogorov-Smirnov-Lilliefors (izquierda, muestra mayor de 50) o Shapiro-Wilk (derecha, muestra menor de 50). Si la Prueba de Normalidad no resulta significativa, se procede desde un punto de vista paramétrico con el T-Test (2 muestras) o la Tabla Anova (más de 2 muestras).
T de Student comparación de medias poblacionales
| Hipótesis nula | H₀: μ₁ – µ₂ = 0 |
| Hipótesis alternativa | H₁: μ₁ – µ₂ ≠ 0 |


Copiar la Tabla de la T de Student en una hoja de cálculo Excel y pegarla (como imagen) en el procesador de texto Word:
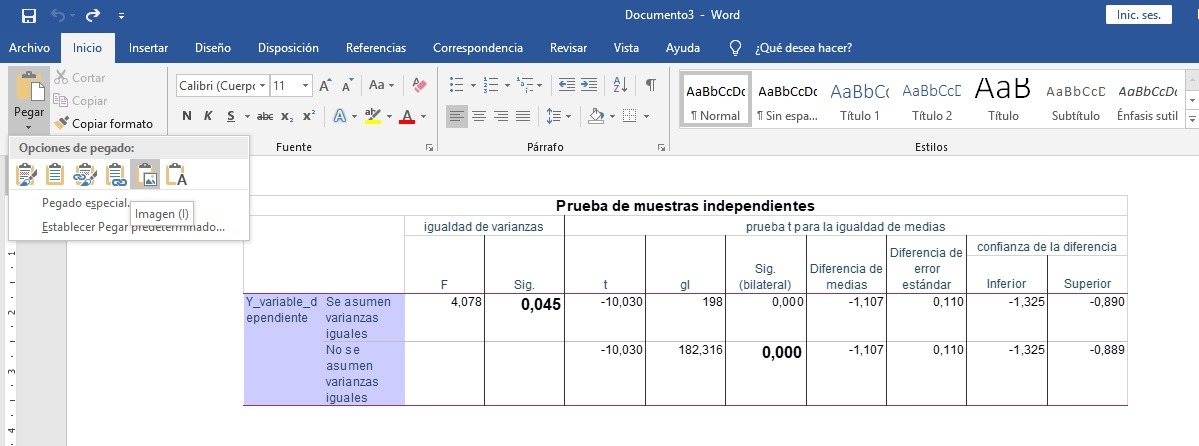
Siempre bajo el cumplimiento del supuesto de Normalidad en nuestra distribución muestral, o de un tamaño de la muestra superior a 50. Se rechaza la hipótesis nula en función de que el significance (Sig.) asociado al estadístico del contraste de la T de Student de comparación de medias sea <0,05 ó <0,01, según el nivel de confianza del estudio. En caso de rechazo de la hipótesis nula, las diferencias en media poblacional entre ambas muestras son estadísticamente significativas. En función del contraste de homogeneidad de varianzas, si su p-valor asociado es mayor que 0,05 se mira el significance bilateral de asumir varianzas iguales; si resulta significativo, esto es, menor que 0.05, se mira el de abajo, que es el p-valor asociado al estadístico de Welch.

Se puede generar una variable suma de los items de una componente/dimensión o suma total de los items, (estimador insesgado, centrado, de mínima varianza) como variable de respuesta dependiente continua, y ver si esta variable suma de comporta de la misma manera (comparar homogeneidad de varianzas e igualdad de medias) en los 2 o más grupos que conforma la variable explicativa independiente, con el correspondiente Test de la T de Student (2 grupos) o Tabla ANOVA (más de 2 grupos).
Tabla ANOVA de 1 Factor con SPSS
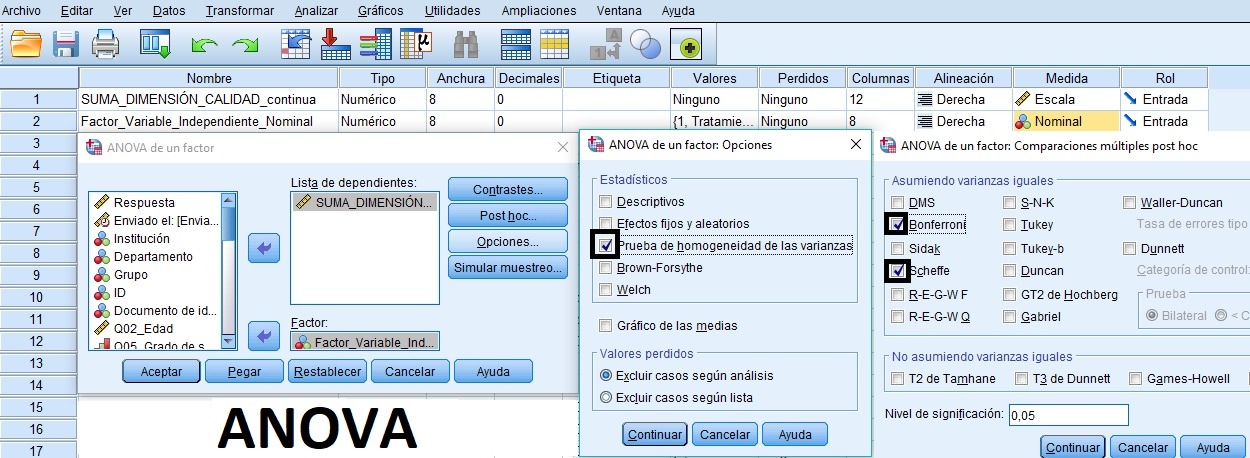
ANOVA con supuesto de homocedasticidad (homogeneidad de varianzas) y pruebas de comparaciones múltiples POST HOC con SPSS.


Partiendo de que se cumplen los supuestos de partida de normalidad y homocedasticidad de la variable dependiente continua en estudio, y como el ANOVA resulta estadísticamente significativo, se procede a realizar las correspondientes pruebas de comparaciones múltiples POST HOC (Bonferroni es la más conservadora), mostrándose significativas las diferencias entre los tratamienntos 1 y 2 (p-valor de 0,037<0.05).
estamatica@gmail.com