Econometría con GRETL en 2026
Siempre partiendo de la teoría económica subyacente sobre el análisis econométrico en concreto, basándonos en una correcta especificación y bajo el estricto cumplimiento de los supuestos de partida de la regresión múltiple, tanto los clásicos, como los del error,
Índice del Artículo
Descriptivos
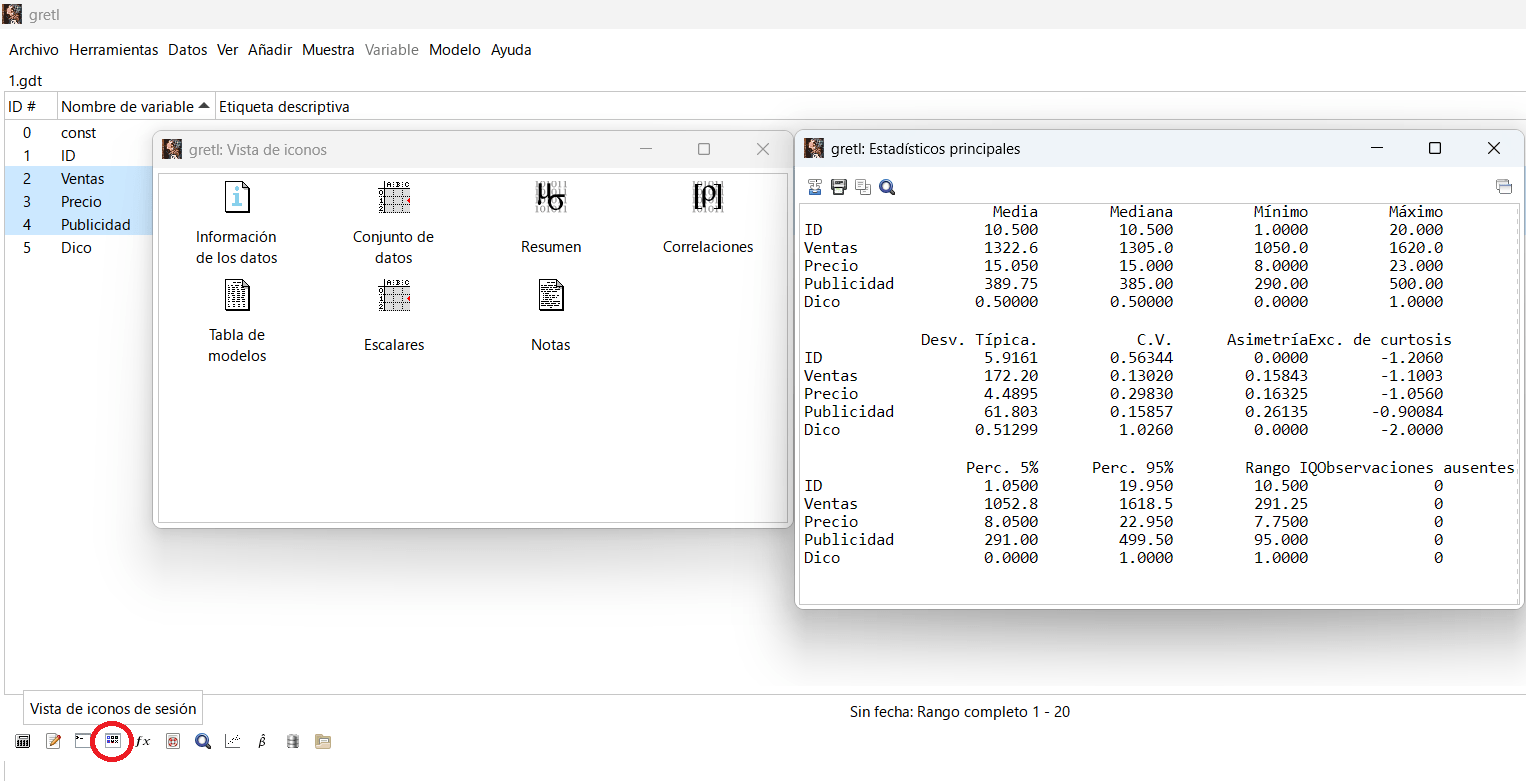
Antes de comenzar con la inferencia, tenemos la opción de ‘Resumen’, con los Descriptivos completos en Gretl, por ejemplo proporciona el CV como medida de dispersión/variabilidad, que la mayoría de los software de estadística no ofrecen por defecto.
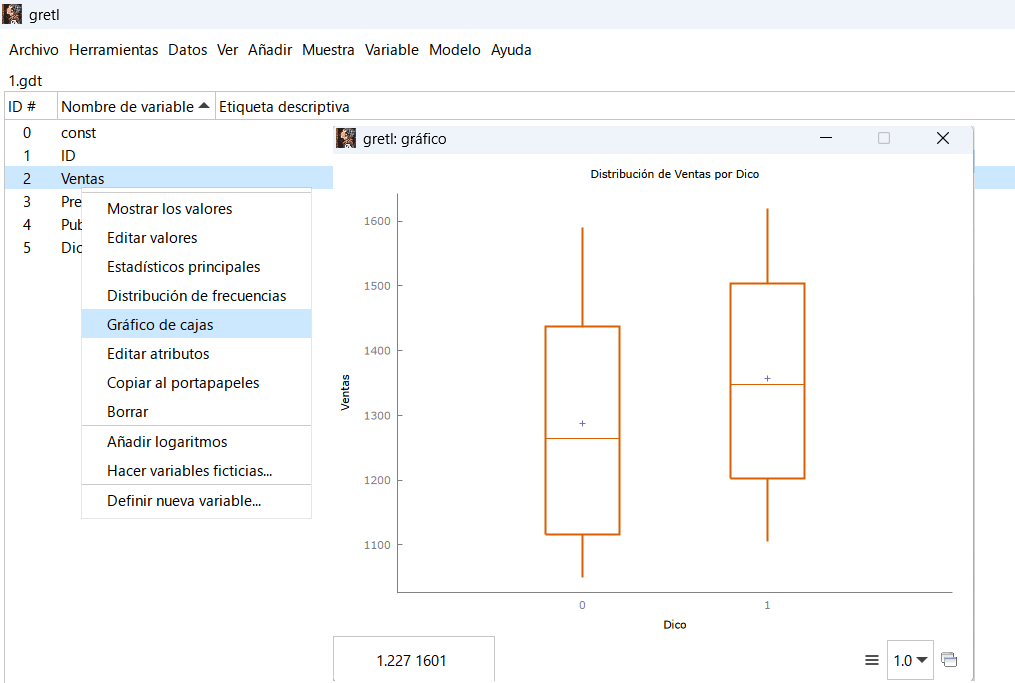
Box-Plot
El gráfico de cajas y bigotes puede servir como detector de valores atípicos (outliers), que además de desvirtuar el resultado del análisis estadístico, puede llevar al incumplimiento de supuestos de partida del modelo de regresión múltiple como puede ser el del normalidad en la distribución de los residuos o errores.
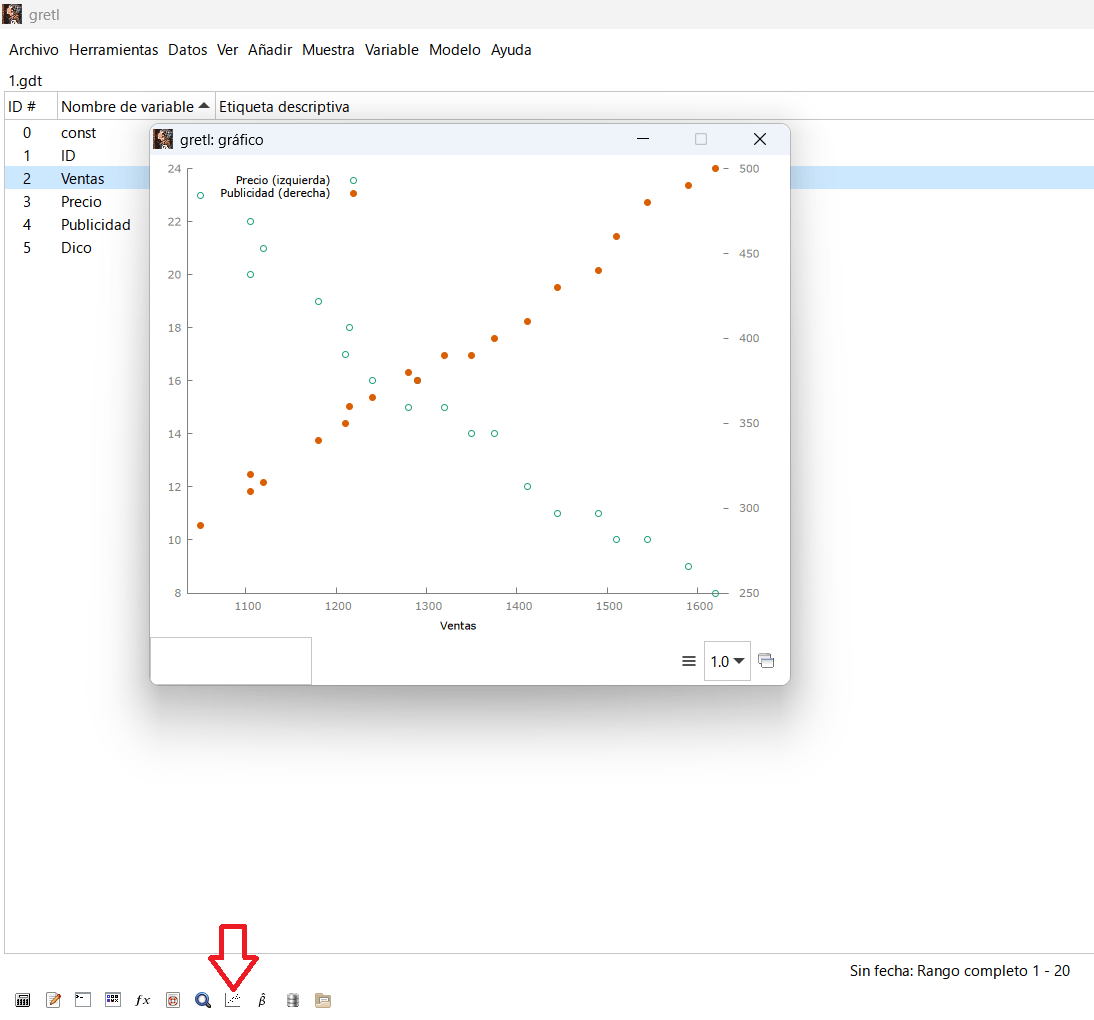
ScatterPlot
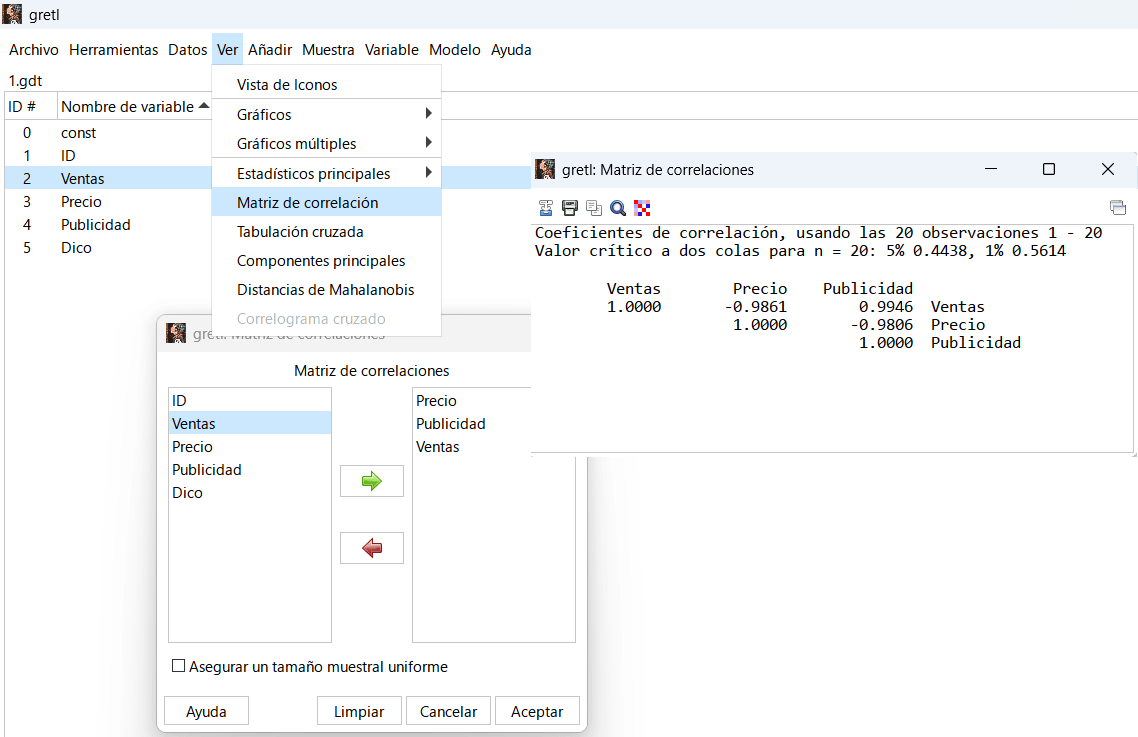
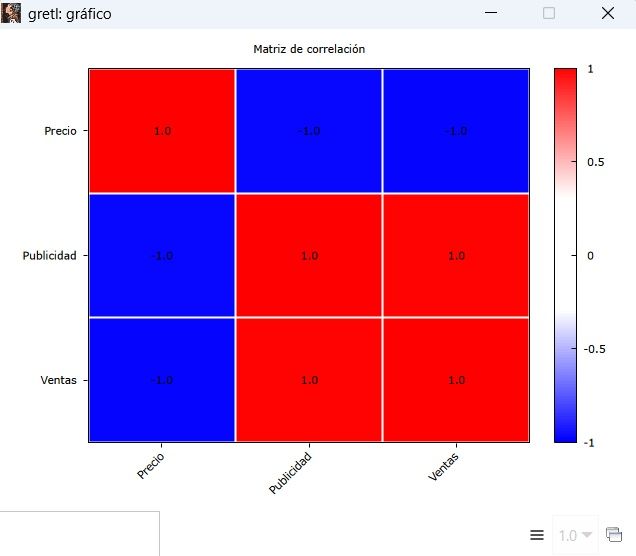
Matriz de Correlaciones
Además de corroborar si existe relación lineal entre las variables, sirve para detectar el cumplimiento o no del supuesto de no multicolinealidad entre las variables explicativas o factores de la regresión múltiple.
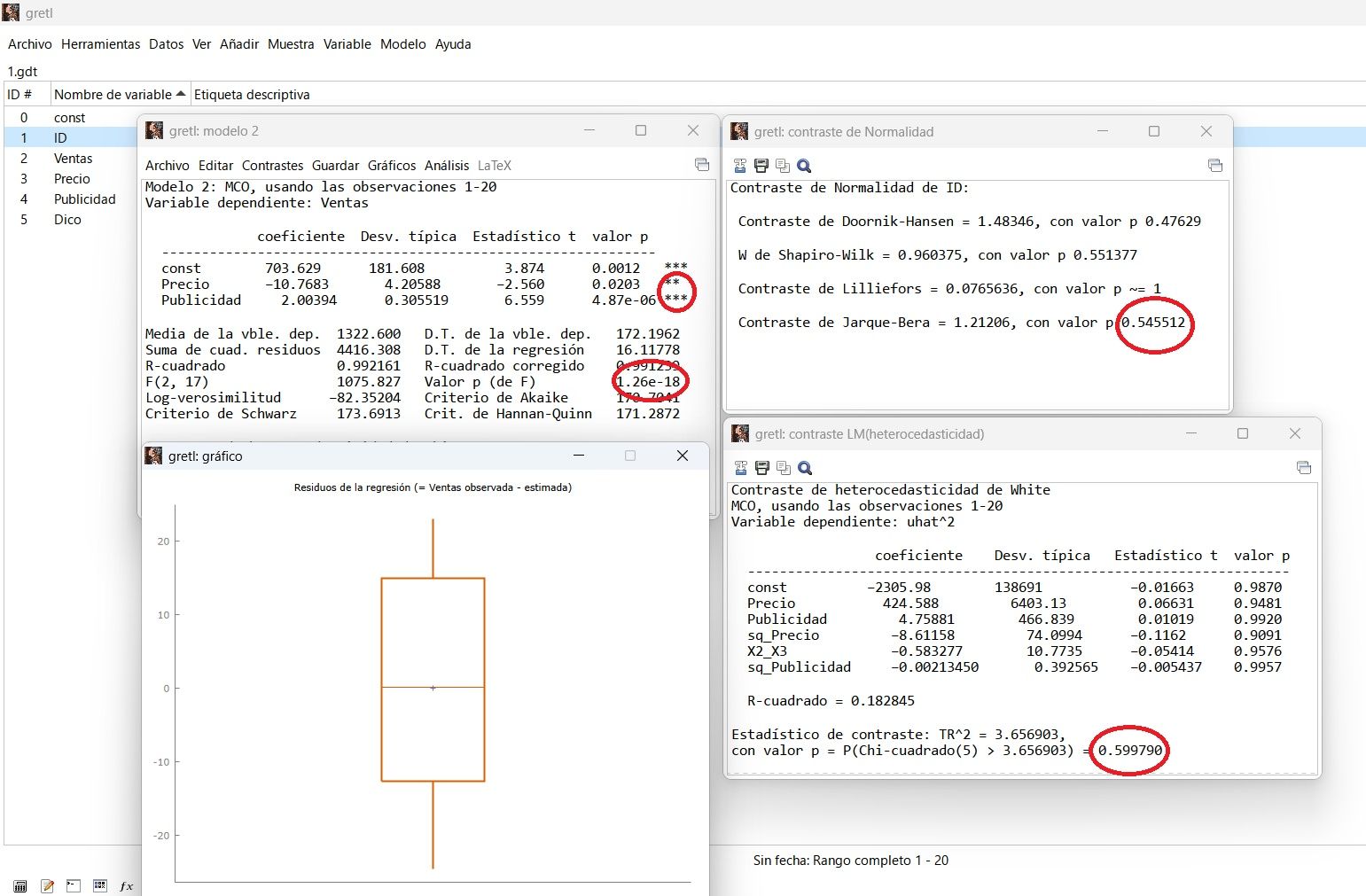
Modelo de Regresión Múltiple
Modelo de regresión múltiple por MCO, con supuestos de partida de normalidad con el test de Jarque-Bera, el más apropiado para modelos econométricos. y el test de homocedasticidad del residuo. Al eliminar variables que no resulten estadísticamente significativas, volviendo a correr el modelo, mejora el R cuadrado corregido y mejora el p-valor de la significatividad conjunta del modelo. Incurrimos en un problema de exogeneidad cuando omitimos una variable relevante en el modelo, que haría subir de una manera importante el R2.
La utilización de una transformación logarítmica sobre la variable dependiente resulta óptima porque mitiga los problemas de asimetría y variabilidad extrema habituales en los precios y porque permite interpretar los coeficientes estimados directamente entérminos de variaciones porcentuales (semielasticidades en el modelo log-lin y lin-log/elasticidades en el modelo log-log), aportando una mayor riqueza analítica desde la perspectiva microeconómica.
Supuestos del modelo
Normalidad del residuo
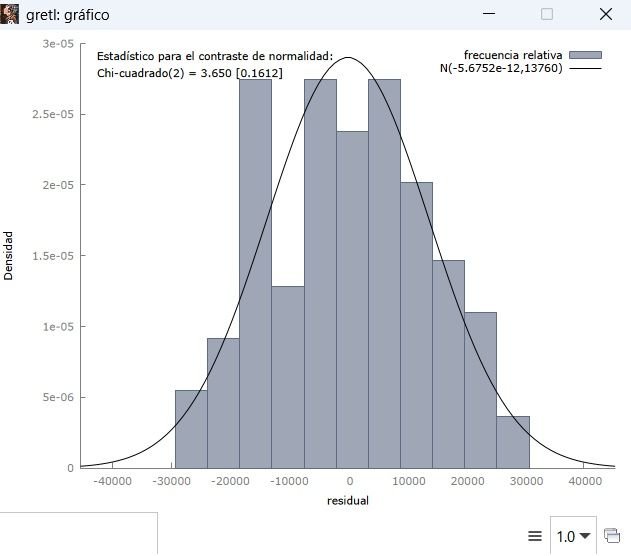
También a partir de la no significatividad estadística en el p-valor asociado al estadístico de Jarque-Bera del residuo o error.
Homocedasticidad
El Test de Breusch-Pagan destaca por tener una mayor potencia estadística cuando la heterocedasticidad es de tipo lineal, ya que al ser un método más específico no pierde precisión. Sin embargo, su flexibilidad es menor, lo que significa que puede fallar si la varianza depende de formas no lineales (como el cuadrado de una variable X^2 sin depender de X). Su principal ventaja práctica es que no sufre con un gran número de variables, puesto que los regresores en su modelo auxiliar crecen de forma lineal (k), manteniendo estables los grados de libertad.
Por el contrario, el Test de White ofrece una flexibilidad máxima, siendo capaz de detectar prácticamente cualquier patrón o forma funcional que adopte la heterocedasticidad. Esta versatilidad tiene un coste: su potencia estadística es menor si la relación es estrictamente lineal, debido a que desperdicia «grados de libertad» estimando parámetros innecesarios. Además, este test sufre notablemente cuando hay muchas variables, ya que al incluir de forma automática cuadrados e interacciones, el modelo auxiliar se satura rápidamente y pierde una gran cantidad de grados de libertad.
No Autocorrelación=Independencia de los residuos
Estadístico de Durbin-Watson entre 1,5 y 2,5 o p-valor del contraste de independencia estadísticamente significativo.
Gráfico del residuo
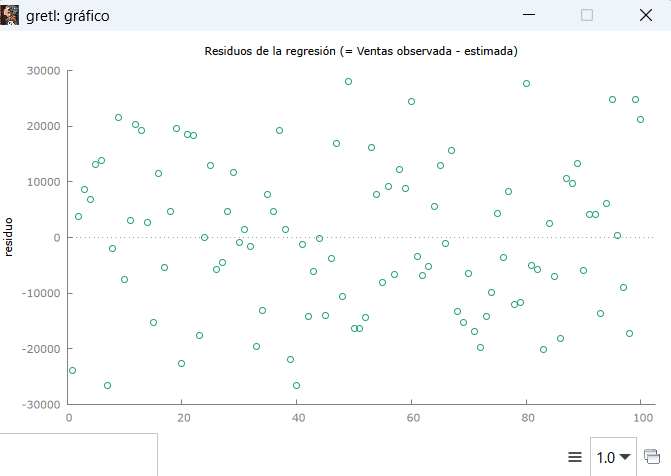
Comportamiento aleatorio-errático, que no tenga forma de altavoz-megáfono o abanico para el cumplimiento de independencia de los residuos.
No multicolinealidad
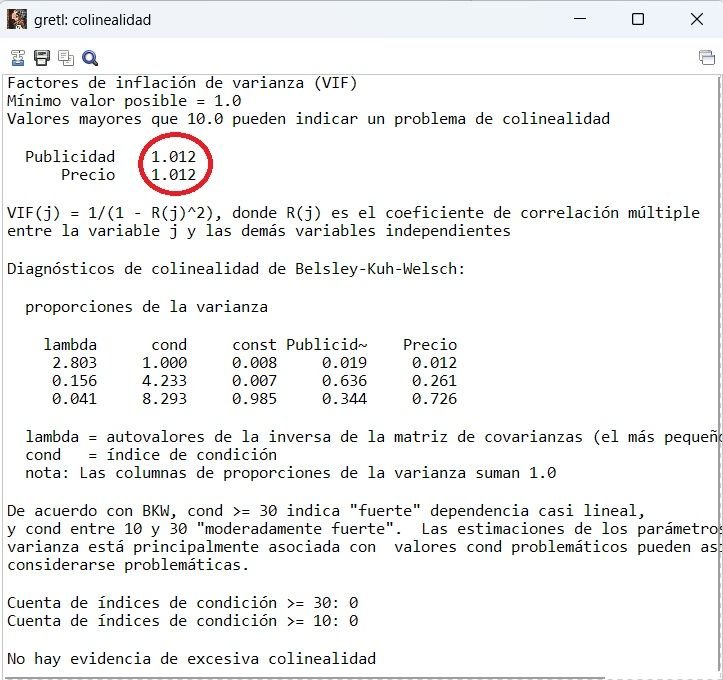
Valores de FIV menores de 10 para que las variables explicativas no aporten información redundante entre sí.
Predicciones
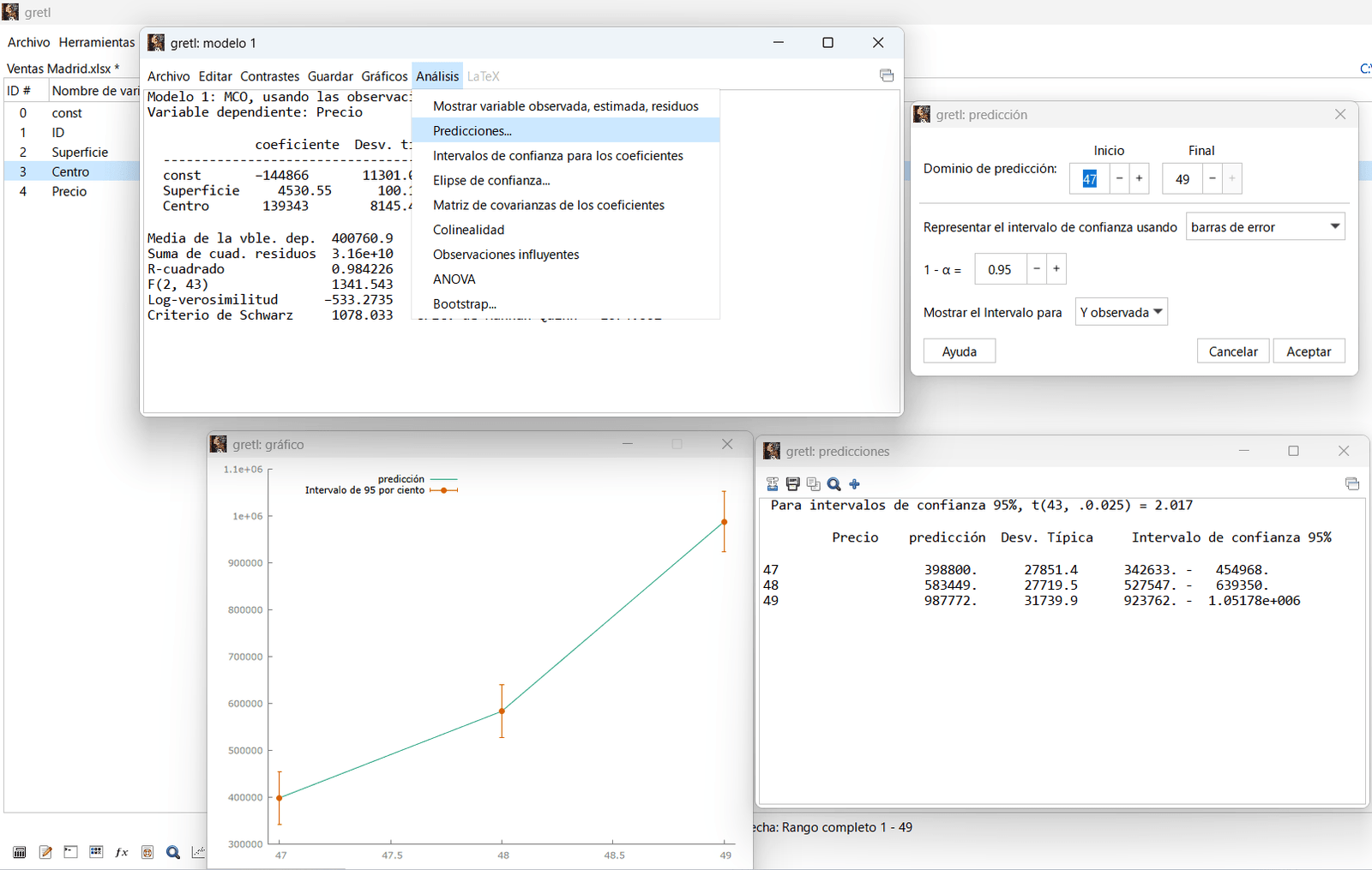
El Error Porcentual Absoluto Medio (MAPE) es una métrica de referencia en Econometría que evalúa la calidad de un modelo predictivo midiendo la desviación de los pronósticos en términos porcentuales. Según los umbrales empíricos de Lewis (1982), un valor de MAPE inferior al 10% se considera una predicción altamente precisa o excelente, mientras que un rango entre el 10% y el 20% define una predicción buena o razonable.
Por su parte, el Coeficiente U de Theil complementa este análisis al actuar como una medida de precisión relativa que compara las predicciones del modelo frente a un estándar básico (un modelo ingenuo o de «no cambio»). A diferencia del MAPE, que solo mide la magnitud del error, la U de Theil acota sus resultados: un valor de 0 indica una predicción perfecta, un valor de 1 significa que el modelo es igual de eficaz que una predicción ingenua, y cualquier valor superior a 1 implica que el modelo funciona peor que el azar o que mantener el último dato observado. Ambas métricas combinadas permiten diagnosticar no solo el tamaño del error de pronóstico, sino también la verdadera utilidad del modelo frente a alternativas simples.
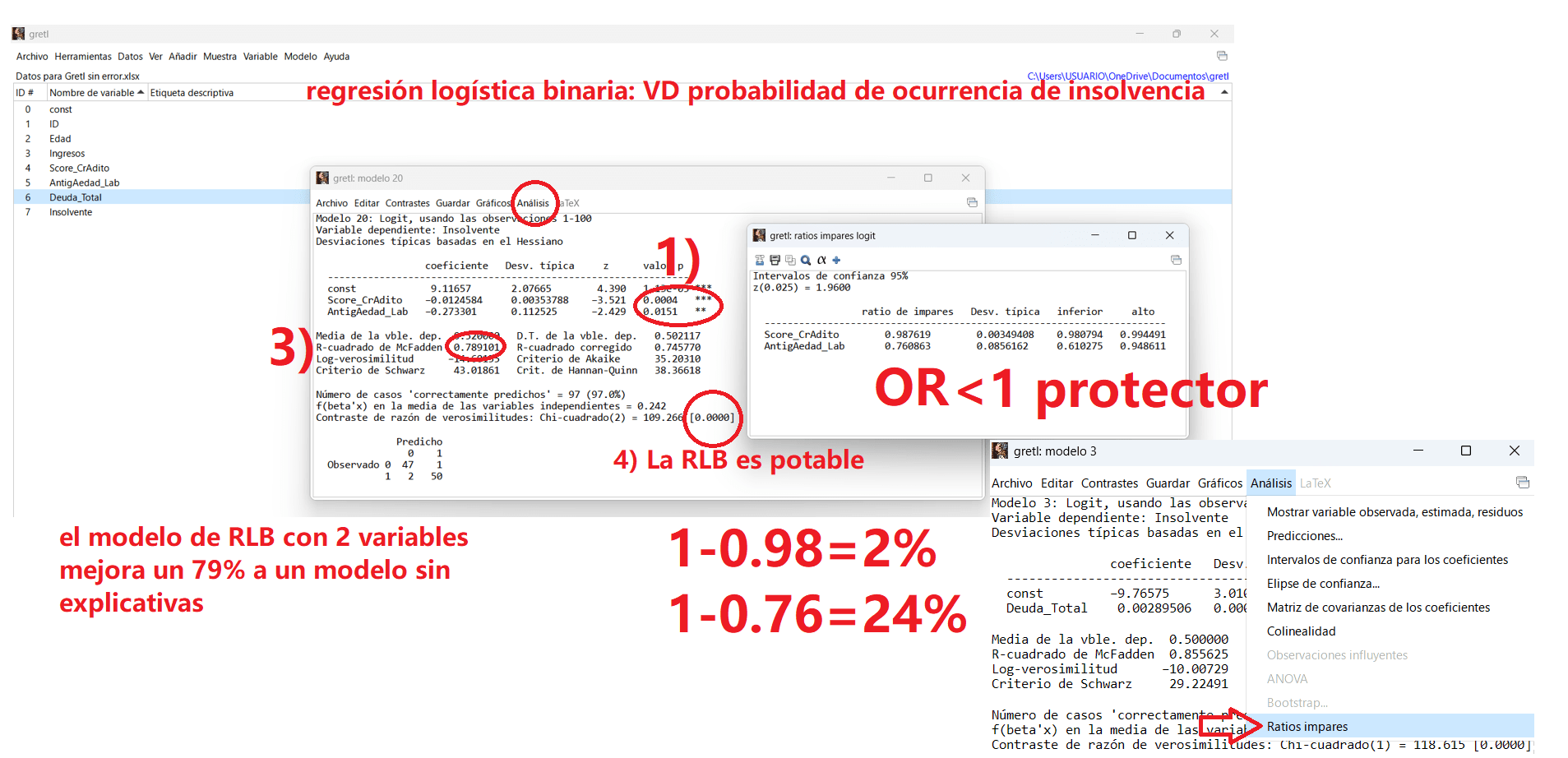
Regresión Logística Binaria
Cómo determinar la probabilidad de ocurrencia de variable de tipo dicotómico (insolvencia Sí/No), a partir de factores como el score crediticio o la antigüedad laboral: