

Encuesta de satisfacción con SPSS
Índice del Artículo
Interpretación estadística de cuestionarios

Fiabilidad y Validez de la batería de ítems
La fiabilidad de los ítems en su conjunto, o de los ítems por componentes o dimensiones subyacentes, la llevamos a cabo a través del alfa de Cronbach, normalmente se considera potable, a partir de valores de 0,7 en adelante. La validez se corrobora a partir del Análisis Factorial Exploratorio, si fuera necesario con rotación Varimax.
Correlaciones
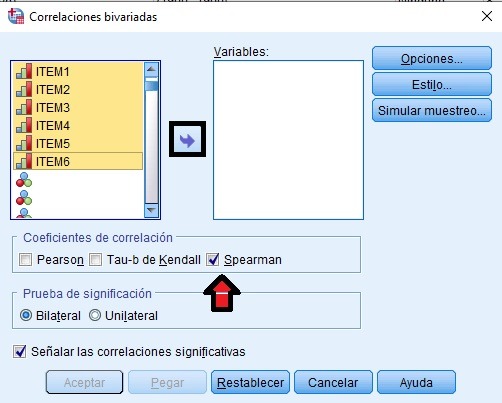
El análisis de correlaciones bivariadas entre los ítems de tipo ordinal en escala Likert (ejemplo: 1 Muy en desacuerdo, 2 En desacuerdo, etc), se lleva a cabo a través del coeficiente de correlación de Spearman, reservando la correlación de Pearson para el cruce de variables continuas de escala.

Las correlaciones son estadísticamente significativas en función del p-valor menor de 0,05 o 0,01, según sea el nivel de confianza fijado para la investigación. En Ciencias Sociales y Psicometría, correlaciones a partir de 0,5 se empiezan a considerar como relativamente importantes.
Definir conjuntos de RESPUESTAS MÚLTIPLES (items dicotómicos)

En primer lugar, se determinan los items de respuesta múltiple (batería de preguntas, normalmente dicotómicas, con más de una opción de respuesta), como una componente, factor o dimensión para SPSS. Se procede a la configuración de la visualización de la tabla de contingencia o tabla cruzada en la ventana de resultados del propio paquete estadístico (Output).


Segmentar archivos
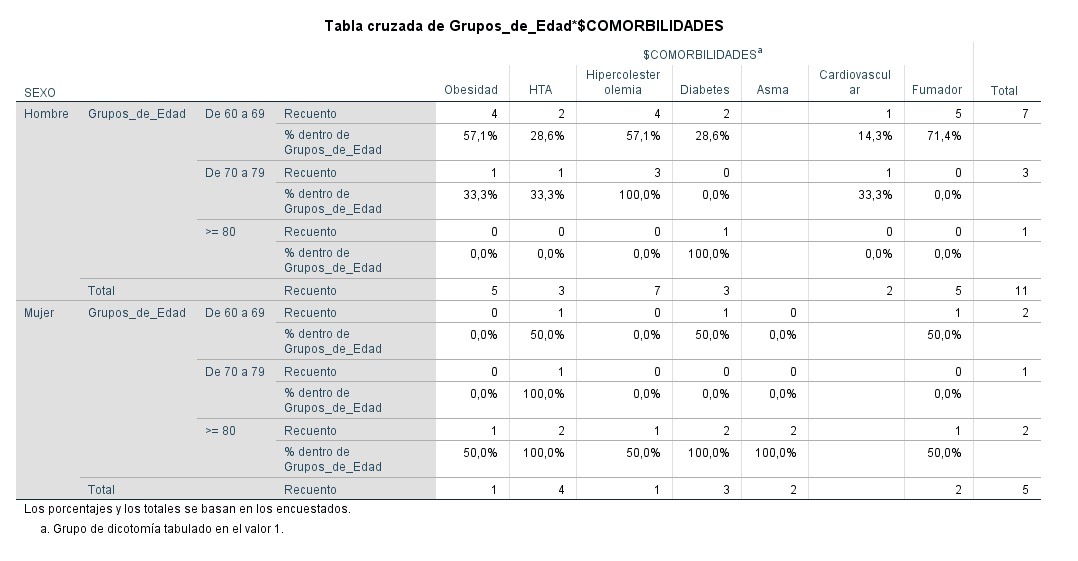
Se pueden llevar a cabo segmentaciones en función de variables, para visualizar posteriormente la tabla de contingencia requerida, en la que se señalan tanto las frecuencias, como los % por fila y columna que sean necesarios. Una opción es exportarla a Excel desde SPSS, para además de formatear las tablas, obtener los gráficos, y configurarlos a medida.

Chi-cuadrado cruce de variables categóricas
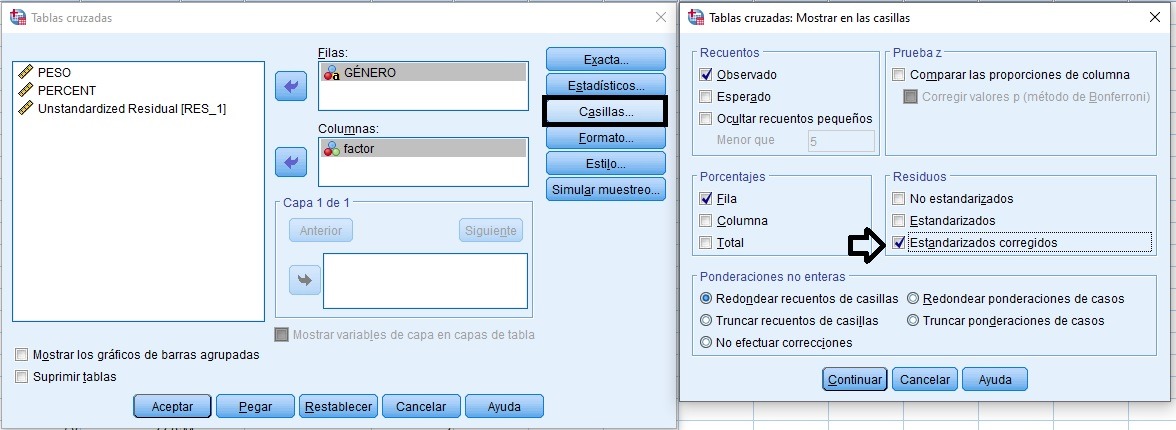
Muestran diferencias estadísticamente significativas aquellas categorías del cruce en las que los residuos tipficados corregidos sean mayores de 1,96.
Contraste de Proporciones
De las categorías de las tablas de contingencia anterior, de las que queramos corroborar si las diferencias son estadísticamente significativas, se procede a realizar el test de comparativa de proporciones, son el software Minitab o Statgraphics.


Test de Hipótesis de la Media
Hipótesis alternativa: La puntuación media de la suma de los items como dimensión/componente es positiva

El test resulta estadísticamente significativo si la suma de los items, como variable dimensión/factor a contrastar, es menor que 0,05. Descriptivamente se comprueba además, si la media de las puntuaciones es efectivamente lo suficientemente mayor a la mitad del valor máximo de la suma de los items.
Muestras relacionadas (PRE versus POST)
Se crea la variable ‘suma’ de cada dimensión, a partir de la suma o la media de la batería de ítems de la componente, que es un estimador centrado, uniforme y de mínima varianza. Se procede a llevar a cabo una prueba no paramétrica para muestras relacionadas para detectar posibles diferencias en mediana entre dichos estimadores suma de cada componente, como es la prueba de rangos con signos de Wilcoxon (equivalente no paramétrico a la T de Student de muestras relacionadas), dada la naturaleza de las propias muestras (ítems tipo Likert) y el no cumplimiento del supuesto de normalidad. Se llevan a cabo los correspondientes análisis estadísticos con el software SPSS en su versión 26. El nivel de confianza que se fija para la investigación es del 95% (p-valores menores de 0,05 inducen significatividad estadística, en todos los análisis a favor de las mediciones de después del tratamiento., lo que se puede comprobar con los estadísticos mediana y rango intercuartílico, los más convenientes en este tipo de pruebas en Bioestadística).

Formas de no contabilizar los missing para la estadística de %

¿Cómo hacer para que SPSS no tenga en cuenta los casos perdidos (missing o celdas vacías, definidas así en vista de variables como entero 99, por ejemplo), a la hora de calcular los % de categorías (filas o columnas, es igual), en tablas de contingencia, es decir que devuelva los % sin tener en cuenta los % de los missing?. No se pueden ‘Seleccionar casos’ en función de un criterio (Si se satisface la condición), de una variable categórica/nominal pura. Las únicas opciones que se barajan son recodificar las categorías en números, o recalcular los % en Excel, sin incluir valores missing, con fórmulas de referencia absoluta. en el propio programa de hoja de cálculo.