


Regresión Múltiple Jerárquica con SPSS paso a paso
- Depuración de datos y detección de valores atípicos de la variable dependiente de respuesta, a través del Diagrama de Caja.
- Análisis Descriptivo.
- Análisis de Correlaciones. (Pearson o Spearman según se detecte normalidad o no).
- Comprobación de los supuestos de partida del modelo de regresión mútiple.
- Bondad del ajuste con el R2 ajustado o % de variabilidad explicada por el modelo asociada.
- Significatividad de los factores (variables explicativas independientes) de cara a la predicción del modelo ajustado de la variable explicada del estudio.
- Modelo de regresión múltiple (GLM).
Índice del Artículo
1. Detectar valores atípicos (outliers) con Box-Plot

Diagrama de Caja y Bigotes de depuración de datos, la mayor parte de las veces imprescindible, de manera previa al análisis estadístico, con variable dependiente de respuesta continua (escala en SPSS). Los casos/filas marcados con un número y un circulito, fuera del bigote inferior y del superior, son considerados atípicos-outliers, susceptibles de ser eliminados de cara a no desvirtuar los resultados de los análisis estadísticos.
2. Análisis Descriptivo
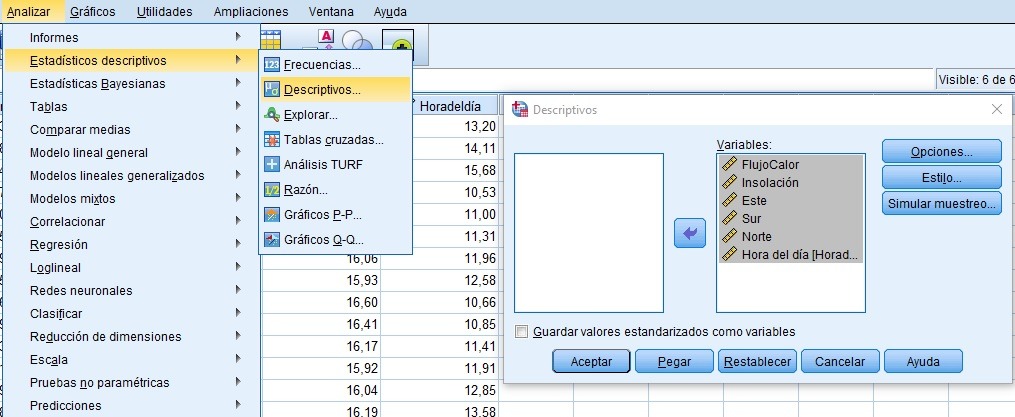
3. Análisis de Correlaciones (Pearson o Spearman)
Ejemplo: No se cumple el supuesto de normalidad para ninguna de las variables en juego en el estudio (p-valor asociado al contraste de normalidad de Kolmogorov-Smirnov- Lilliefors menor que 0,05, por lo tanto, estadísticamente significativo, para un tamaño muestral mayor de 30-50), por lo que se procede desde un punto de vista no paramétrico (se rechaza la Ho), a la hora de realizar un análisis de correlaciones entre las variables, con el coeficiente de correlación Rho de Spearman, equivalente al coeficiente de correlación lineal de Pearson en el caso de violarse el supuesto de normalidad.
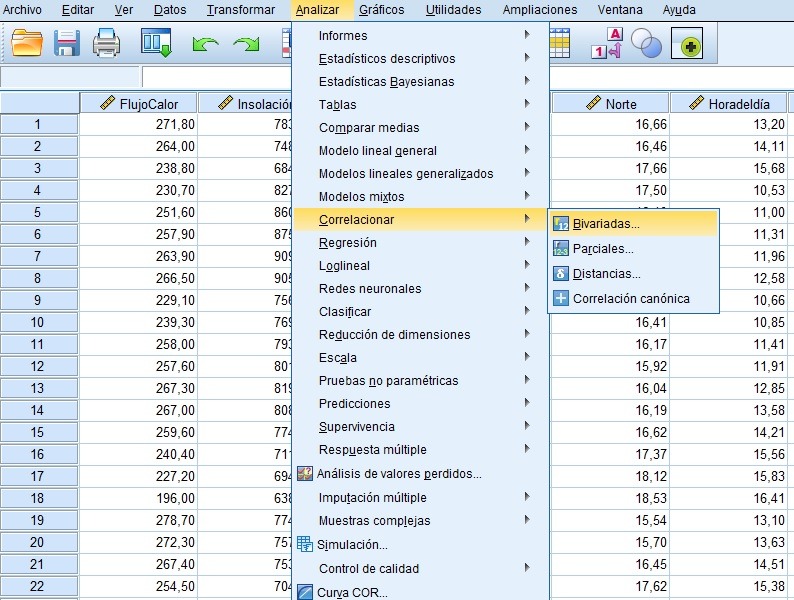

En función del grado de correlación con la variable dependiente de respuesta, la primera variable explicativa o factor a entrar a formar parte del modelo de regresión jerárquica, será aquella que presente un mayor coeficiente de correlación con la variable explicada. También se trata de que no se aprecie correlación excesiva entre las propias variables independientes, para no incurrir en un problemas de colinealidad, o información redundante de las mismas.
4. Supuestos de partida del modelo

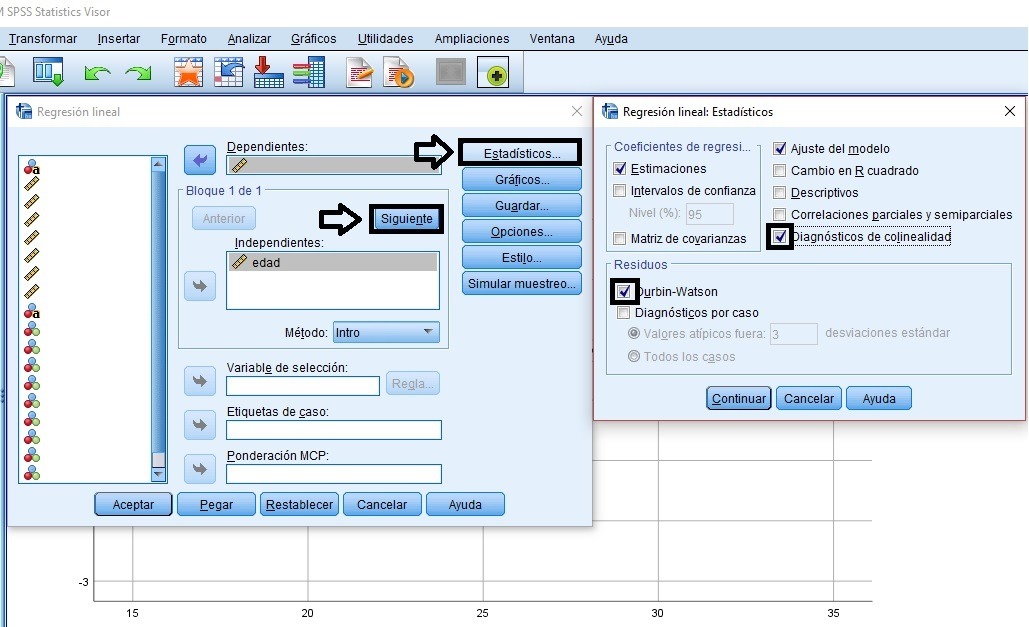
Supuesto de independencia de los errores con estadístico de Durbin-Watson, con valores entre 1 y 3 (1,597 en ejemplo). El modelo de regresión múltiple explica el 87,7% de la variabilidad de la variable dependiente o de respuesta, por lo que considera un buen modelo predictivo (se mira el R2 ajustado).

Supuesto de no multicolinealidad con todos los VIF (Factor de Varianza Inflada) de las variables explicativas con valores entre 1 y 10, por lo que se cumple el supuesto de partida de cualquier regresión múltiple jerárquica.
5. Modelo de regresión múltiple jerárquico (GLM)
El análisis estadístico propuesto en este caso, es un GLM, con supuestos de partida comola independencia de los errores (Durbin-Watson entre 1 y 3 y no multicolinealidad, VIF entre 1 y 10). Análisis de correlaciones no paramétrico mediante coeficiente de correlación de Spearman, pues no se cumple hipótesis de Normalidad, y finalmente, regresión múltiple jerárquica (las variables explicativas van entrando en el modelo en función de su grado de correlación con la variable de respuesta), para detectar la significatividad de los factores, de cara al modelo de predicción de la variable dependiente. El R cuadrado ajustado expone la % de variabilidad explicada por el modelo GLM y la bondad del ajuste planteado:

Resultan estadísticamente significativas, de cara a predecir el modelo, aquellas variables independientes cuyo p-valor asociado sea menor que 0,05. Los coeficientes de regresión Betas exponen, valores en cada caso, lo que aumenta (valor negativo, disminuye) la variable dependiente, cuando la independiente se incrementa en una unidad, permaneciendo el resto de las variables constantes. El término independiente (constante) no se suele interpretar en cuanto a su significatividad estadística ,aunque si entra (normalmente) a formar parte de la fórmula de la ecuación del modelo predictivo. Si los valores de probabilidad asociada (Sig.) son muy pequeños, se reflejan en los TFM, TFG, Tesis, Abstract científico como p<0,001, por ejemplo: (t=-8,48, p<0,001), es decir, valor del estadístico del contraste, p-valor asociado, ambos entre paréntesis, separados por coma o punto y coma, y siempre siguiendo las normas APA, Chicago, etc.
De manera definitiva, se lleva a cabo una última regresión jerárquica con las variables que resultan estadísticamente significativas en el último modelo.
La ecuación del modelo de regresión múltiple (modelo predictivo) es de la forma:

ui: si se trata de un modelo econométrico (perturbación aleatoria)
ei: si se trata de un modelo estadístico de regresión múltiple (error o residuo aleatorio)
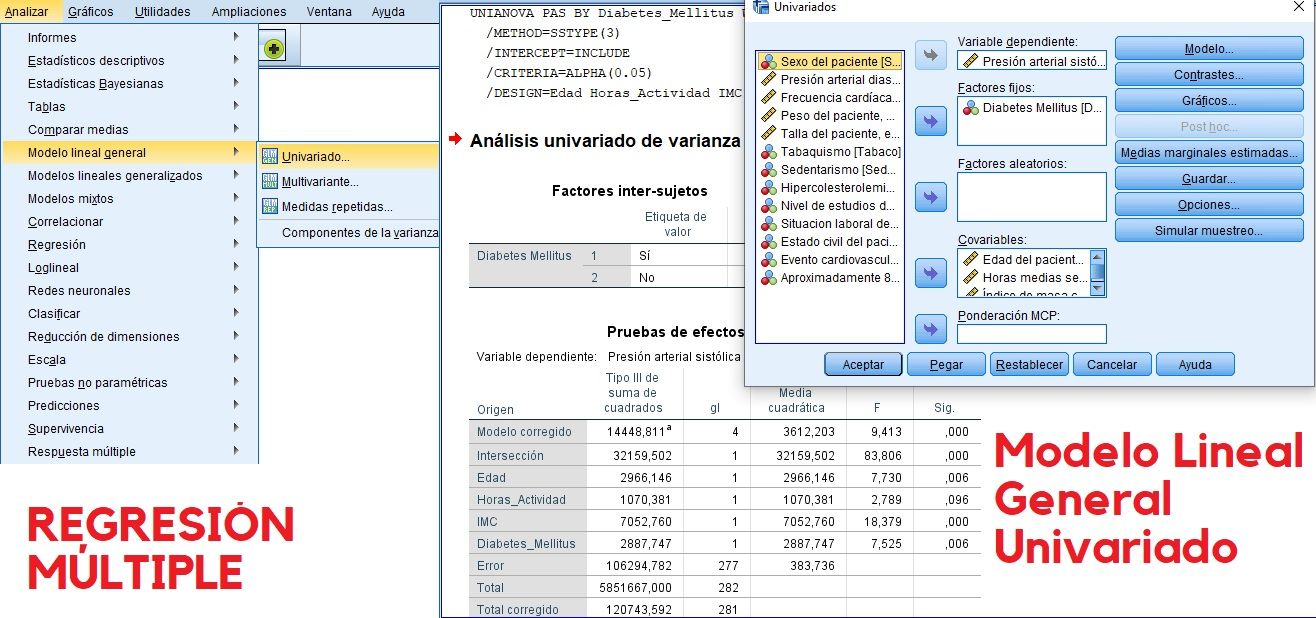
MODELO UNIVARIADO DE REGRESIÓN
Se trata de una base de datos de personas atendidas en un centro de salud para realizar un estudio de factores de riesgo cardiovascular. Para estudiar la asociación entre la variable de respuesta ‘TAS’ (tensión arterial sistólica), y el resto de variables propuestas, se lleva a cabo un modelo predictivo de regresión múltiple, de variable dependiente cuantitativa, respecto a las independientes explicativas: cuantitativas y cualitativas dicotómicas.
Botón Modelo

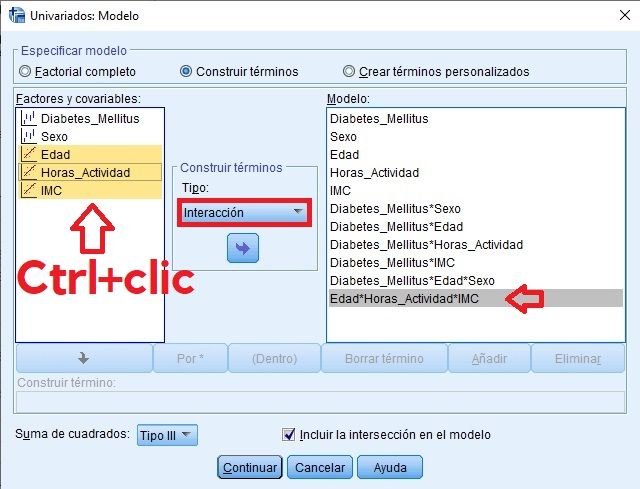
Se seleccionan/se prueban como efectos principales las variables que se presupone que van a resultar estadísticamente significativas al 5% (p-valor<0,05) o al 10% (p-valor<0,1), en función de la importancia de las mismas en relación a nuestro estudio. Posteriormente se reflejan las interacciones que pudieran ser significativas, con el mismo criterio.

En la Tabla del visor de resultados, se puede comprobar la significatividad estadística del modelo de regresión múltiple general univariado, a partir de un p-valor menor de 0,05 de la columna del Sig., la variables como efectos principales y las interacciones solicitadas, se muestran estadísticamente significativas de cara a predecir el modelo de regresión.
Opciones
Gráficos

