


Trucos y Tips para SPSS
Índice del Artículo
Fusionar archivos de SPSS


En el caso de tener la necesidad de fusionar o fundir archivos, existe la posibilidad de llevarlo a cabo mediante la fusión de los casos (filas) de cada una de las bases de datos. o fusionar las variables (columnas) de ambas bases de datos, es decir los 2 archivos .sav de SPSS.
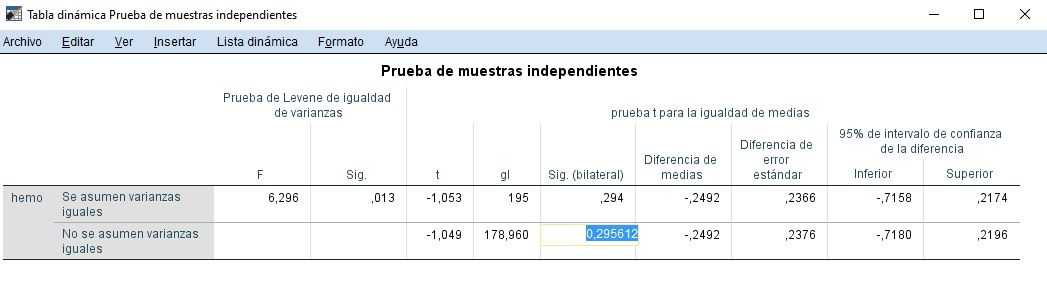
Visionar el valor exacto del p-valor (Sig.)
 Doble clic en tabla en concreto de SPSS en ventana de resultados (archivo .spv), y doble clic en valor de la probabilidad asociada al estadístico del contraste o ‘Sig. (bilateral)’.
Doble clic en tabla en concreto de SPSS en ventana de resultados (archivo .spv), y doble clic en valor de la probabilidad asociada al estadístico del contraste o ‘Sig. (bilateral)’.
Seguir trabajando en el mismo visor de resultados al abrir nueva sesión

Recuperar ventana de resultados previamente realizados en SPSS (es necesario haber guardado en la sesión anterior dichos resultados con un nombre), y continuar realizando nuevos análisis estadísticos, que se van visionando a continuación, al final del archivo de resultados (.spv).
Exportar resultados de tablas y gráficos de SPSS a Word
Dentro de los trucos para SPSS, uno de lo más recurrente como es exportar los resultados de tablas y gráficos de SPSS al procesador de texto Word, para posteriormente dar formato siguiendo las normas APA o el que sea requerido. Es importante que no se encuentre activo ningún gráfico ni tabla si lo queremos es exportar todo lo que hay en el visor/ventana de resultados (output) de SPSS:


Seleccionar varias tablas a copiar a la vez en Word de ventana de resultados de SPSS

Reducir Tablas de SPSS en Word

Buscar el punto de referencia disminuyendo el Zoom de Word, para encontrar el cuadradito y poder reducir la tabla hasta que ocupe el área de impresión de nuestro trabajo en Word.
Segmentar archivos en función de variables que forman grupos
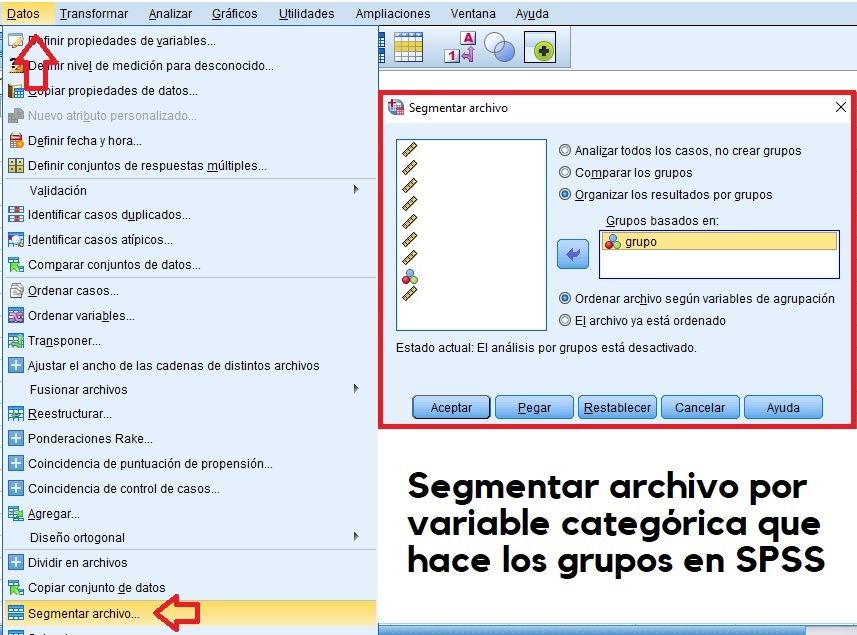
Si lo que se trata es de generar estadísticas por separado en función de variables susceptibles de formar grupos, como puede tratarse de segmentación en función el Sexo, grupos de Edad, nivel de estudios, el IMC, etc.
Seleccionar casos si cumplen una determinada condición lógica

Como seleccionar solo los casos que cumplen una determinada condición lógica (y/o), en el caso de tratarse de un literal (categoría de variable nominal), va entre comillas dobles en la condición, como ocurre siempre en el código de SPSS.
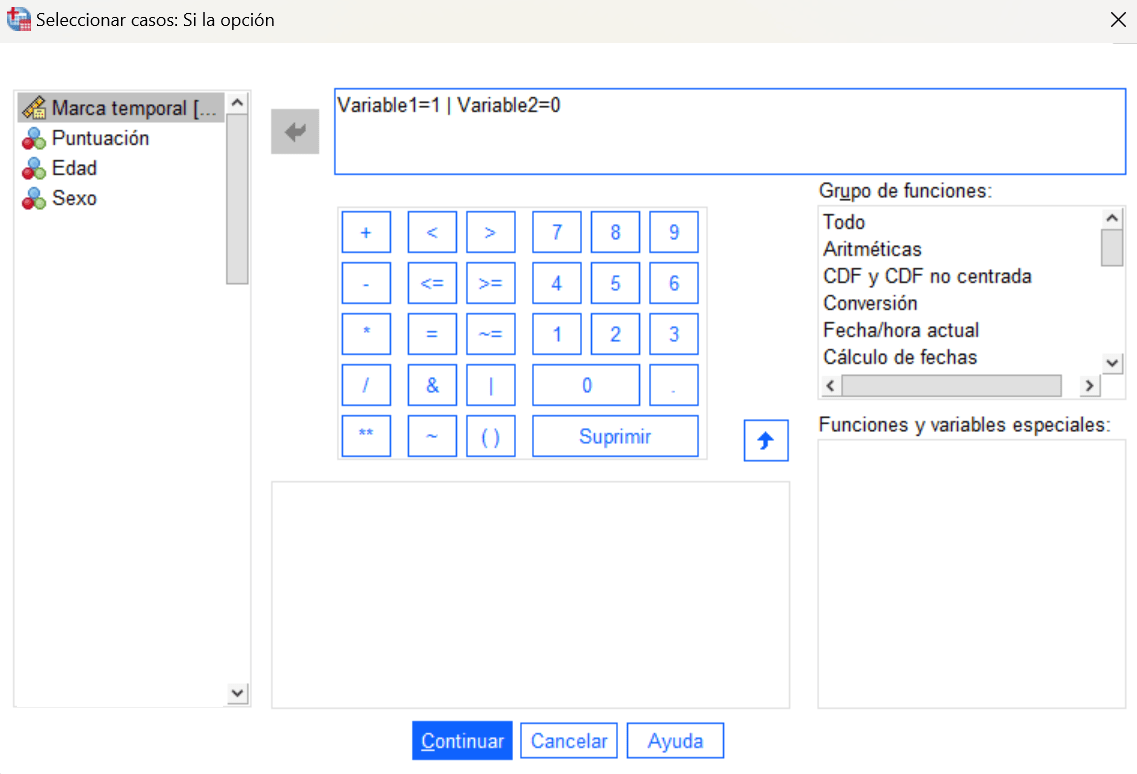
Eliminar casos que no cumplen la condición

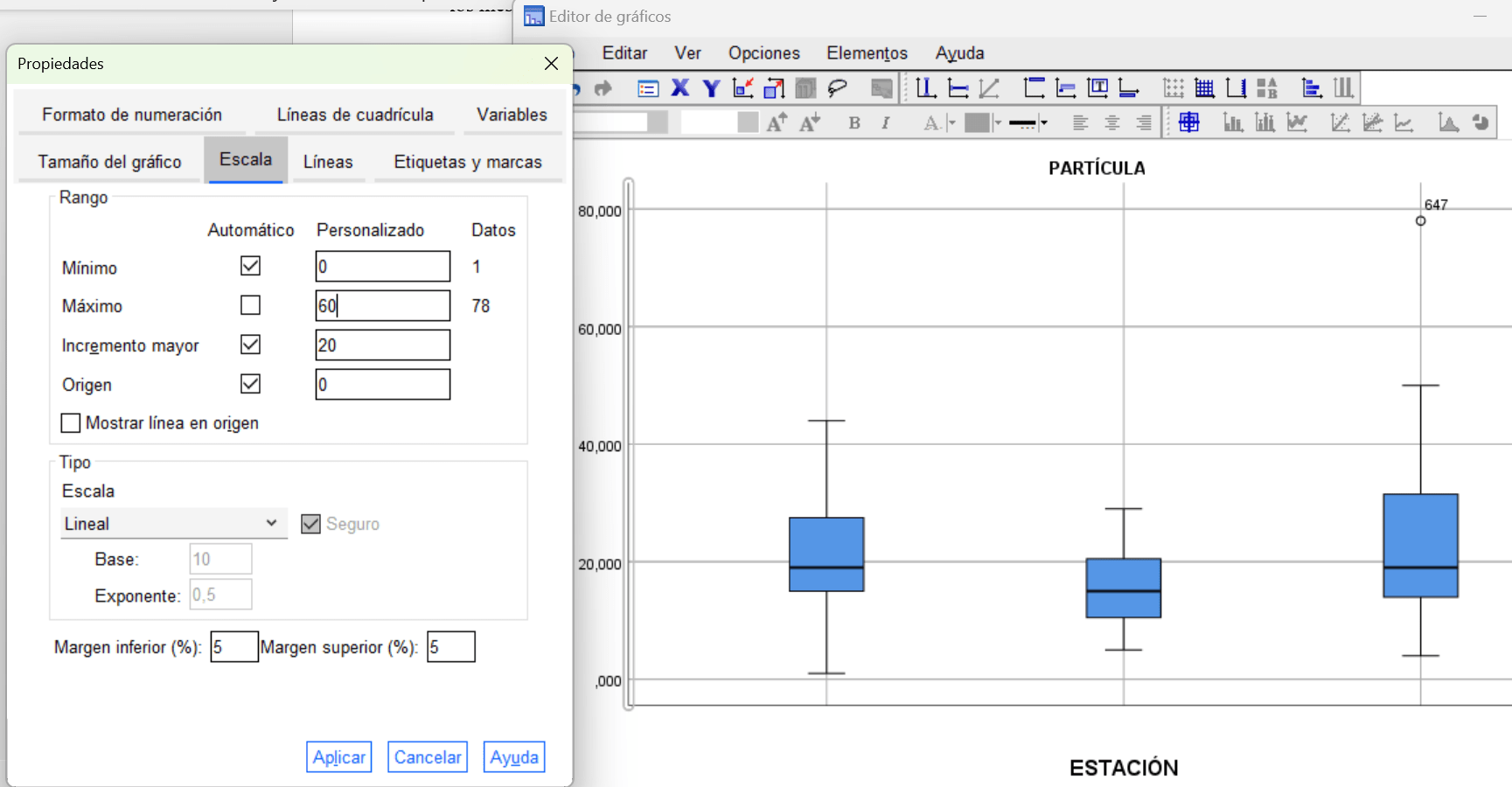
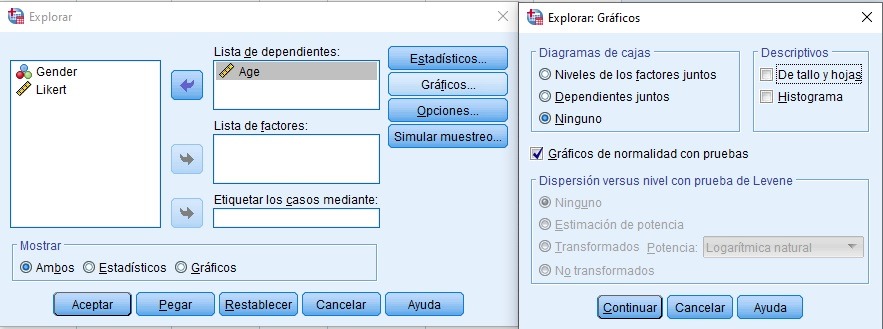
Generar gráficos de caja o Box-Plot por grupos en comando ‘EXPLORAR‘
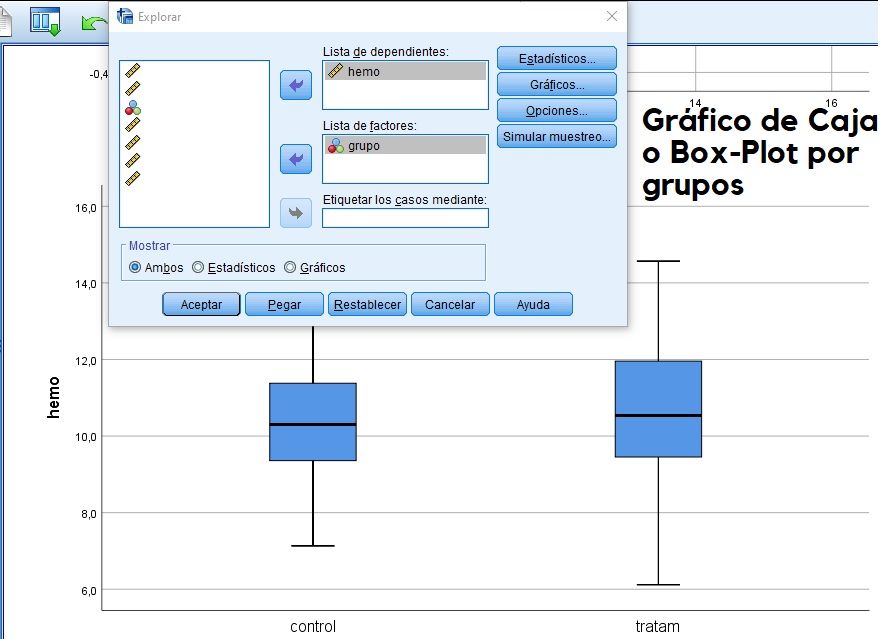
Eliminar valores atípicos (outliers)


Se consideran atípicos los valores inferiores a Q1–1.5·RIC, o superiores a Q3+1.5·RIC (donde Q1 es el primer cuartil y Q3 el tercer cuartil, y RIC es el recorrido intercuartílico, es decir, Q3-Q1, o lo que es lo mismo, entre qué 2 valores se encuentra el 50% central de la distribución). Si se trata se valores atípicos extremos, sustituimos el valor 1,5 por 3 en la fórmula.


Considera como casos perdidos por el sistema aquellos casos por debajo y por encima de los bigotes del gráfico o diagrama Box-Plot.
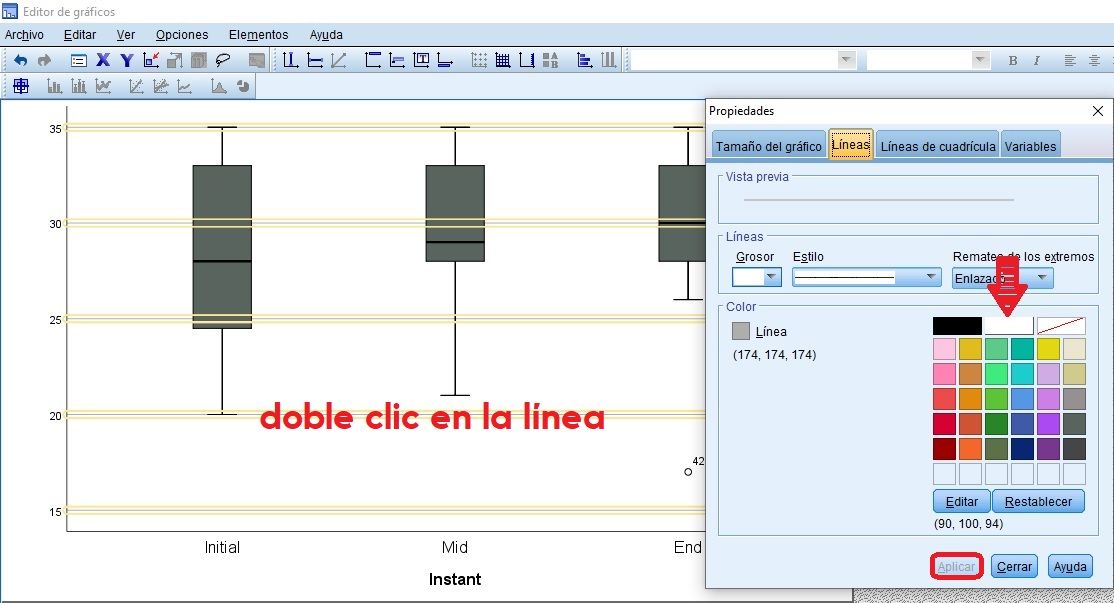
Quitar líneas de fondo en Gráficos
Graficar Intervalos de Confianza
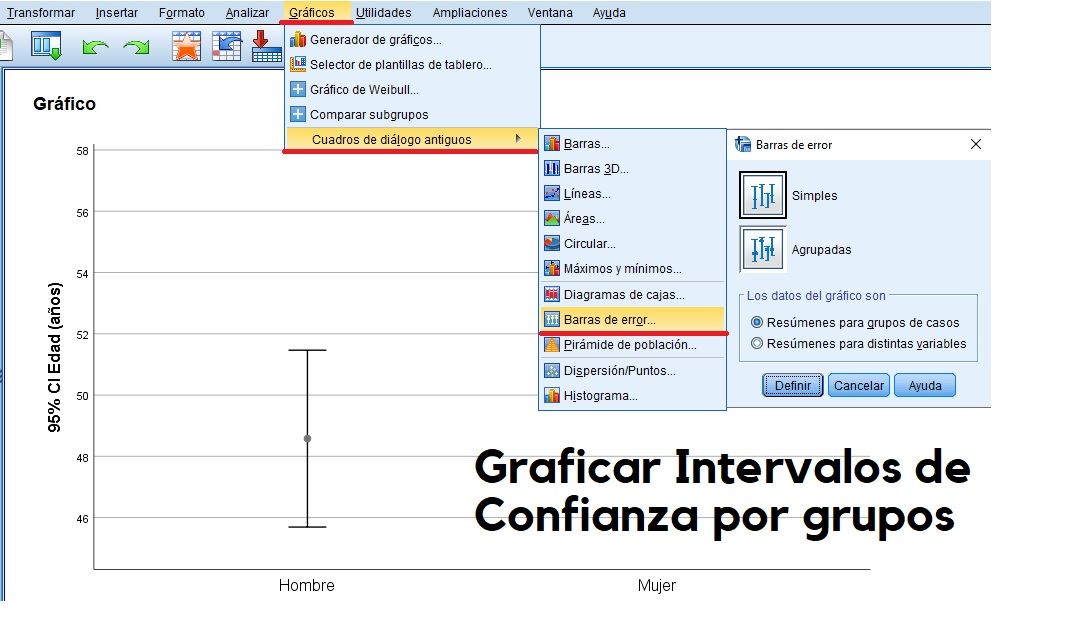
Gráfico de intervalos de confianza al 95% de la variable continua Edad, para los grupos que conforma la variable categórica Sexo.
Configurar gráficos (colores) y guardar y aplicar como plantilla
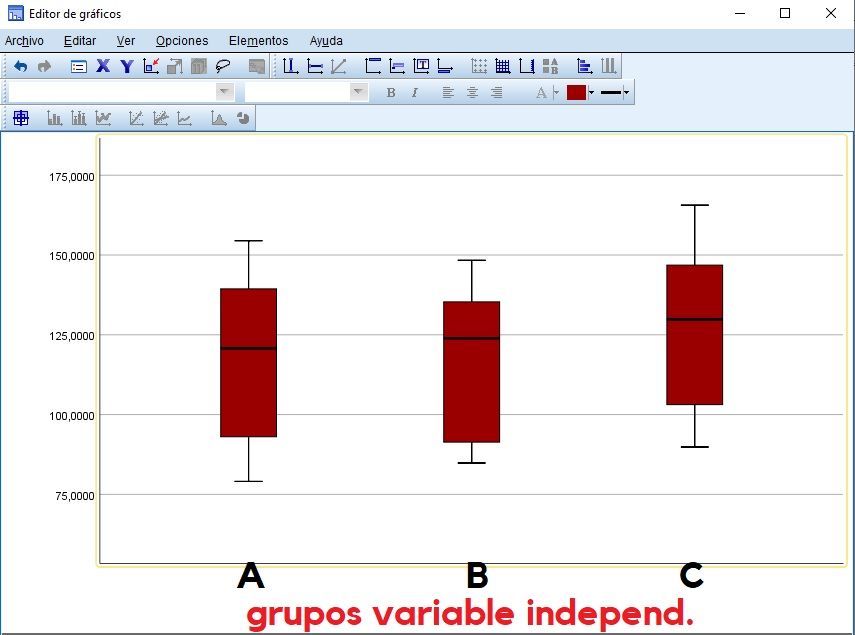

Si se marca la casilla de verificación de ‘Toda la configuración’ (o las que se requiera en concreto), existe la opción de guardar la plantilla de un gráfico en concreto y luego aplicarla en otro, a modo de la brocha de copiar formato de los objetos de Microsoft Office.
Cambiar escala del eje derivado del gráfico
Botón derecho en blanco sobre el gráfico: MOSTRAR EJE DERIVADO
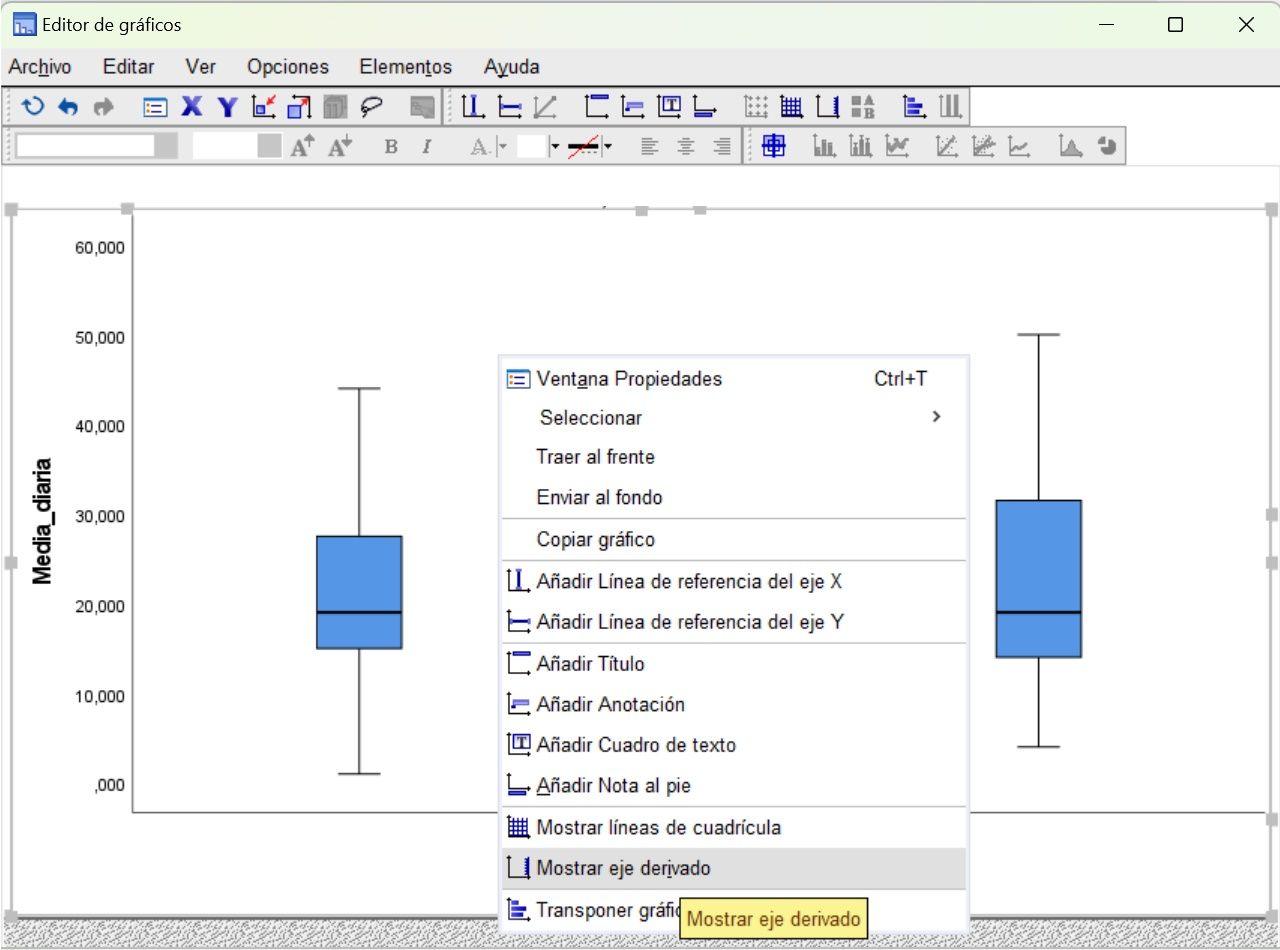
Botón derecho, de nuevo: OCULTAR EJE DERIVADO
Graficar categorías de variables de respuestas múltiples
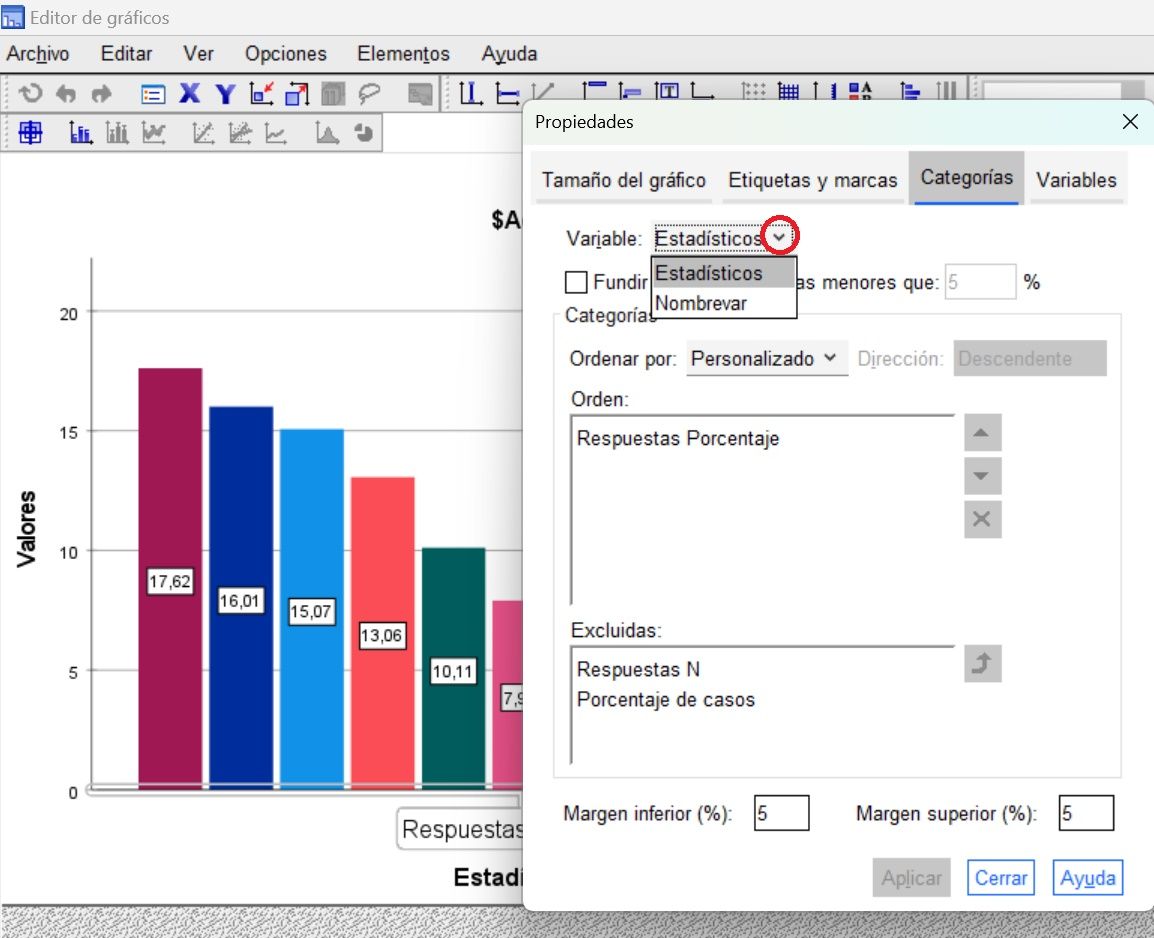
Graficar eliminando los totales de respuesta y los porcentajes de casos y ordenar ‘PERSONALIZADO’: Descendente, seleccionando ‘ESTADÍSTICOS’ en el desplegable de variable.
Recuperar cuadros de diálogo recientes

Existe la opción en SPSS de recuperar cuadros de diálogo recientes ya utilizados, sin tener que configurar el menú de comandos, en el caso de hacer una modificación al análisis estadístico del visor de resultados, o volver a realizar un contraste, descriptivo, correlación o gráfico, previamente realizado.
Variables definidas en intervalos con frecuencias absolutas

Introducir la marca de clase del intervalo de las variables en una columna, y en otra las correspondientes frecuencias absolutas, de esta manera se pueden obtener descriptivos, percentiles, medidas de dispersión, gráfico de caja, etc, de variables definidas en tabla de frecuencia en intervalos.
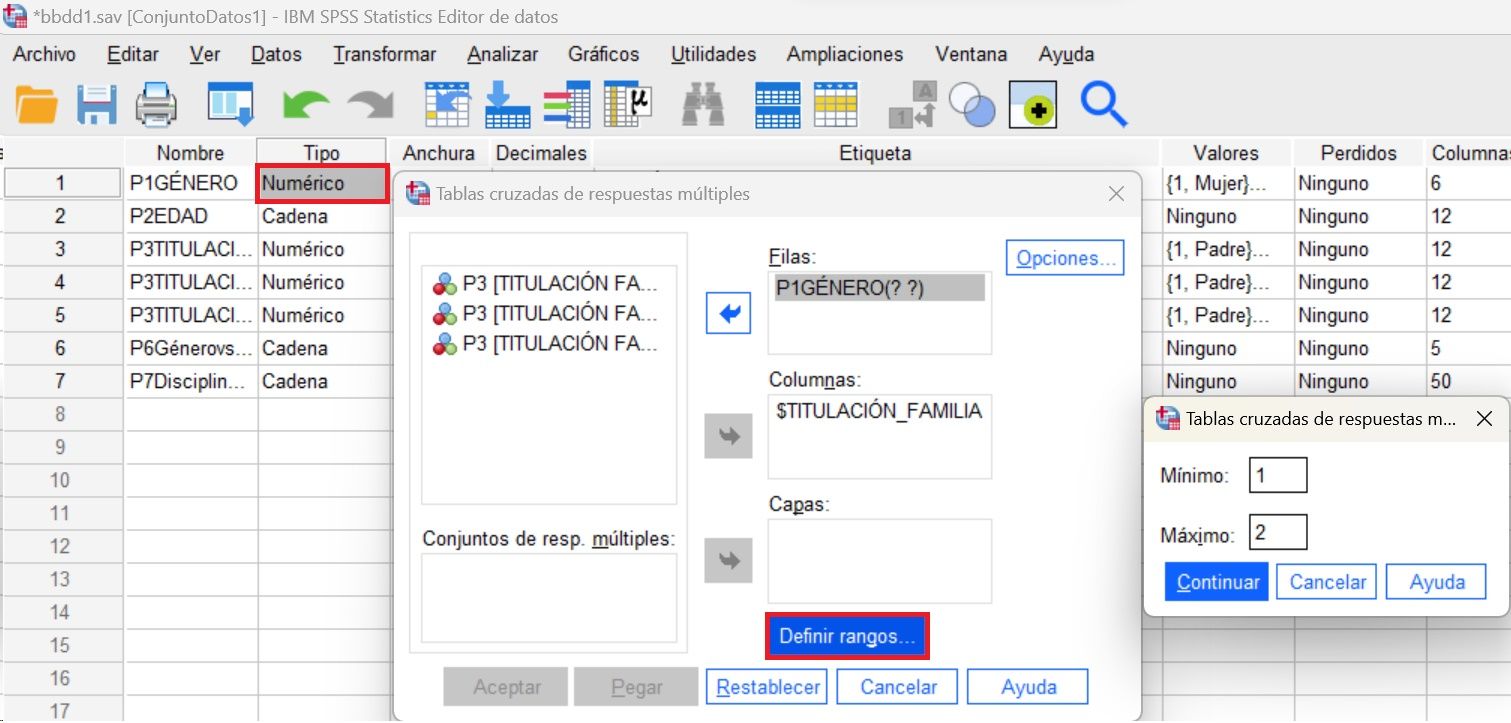
Analizar preguntas de respuesta múltiple
En el caso de tratarse de preguntas o variables de múltiple respuesta, por ejemplo items de un cuestionario en que las personas puedan seleccionar más de una opción, se plantea el inconveniente de no poder codificar más de una variable de respuesta, y no es suficiente con generar una tabla de frecuencias absolutas para cada categoría de respuestas.

Variables ficticias o dummies
En el caso de tratarse de una regresión, ya sea múltiple, logística binaria o logística multinomial, hay que generar tantas variables dummies dicotómicas, como categorías tenga la variable nominal menos 1, si la misma tiene 3 categorías o más. Las variables generadas se recodifican en 0 (ausencia) y 1, siendo la interpretación de los valores de la ODDS RATIO en función de los codificados como 1. Veamos un ejemplo de una variable con 3 categorías, luego se generan 2 variables dummies con los siguientes valores. La interpretación recae sobre la variable ‘Educación Primaria’, que se toma como referencia:
| DUMMY1 | DUMMY2 | |
Primaria | 0 | 0 |
Secundaria | 1 | 0 |
Universidad | 0 | 1 |
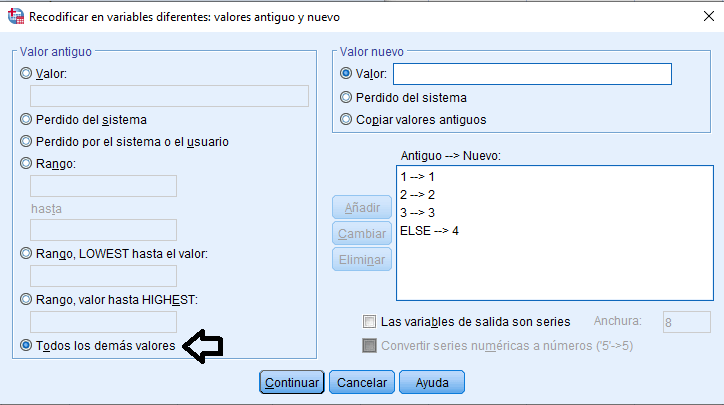
Recodificar en distintas variables (ELSE)

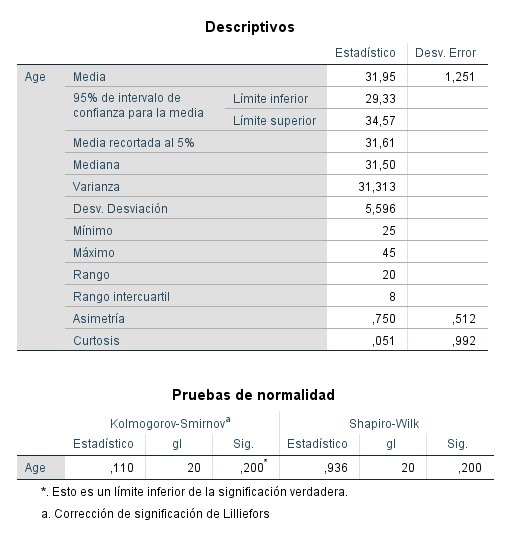
Test de Normalidad, limpio
Regresión múltiple jerárquica con supuestos de independencia de los errores y no multicolinealidad
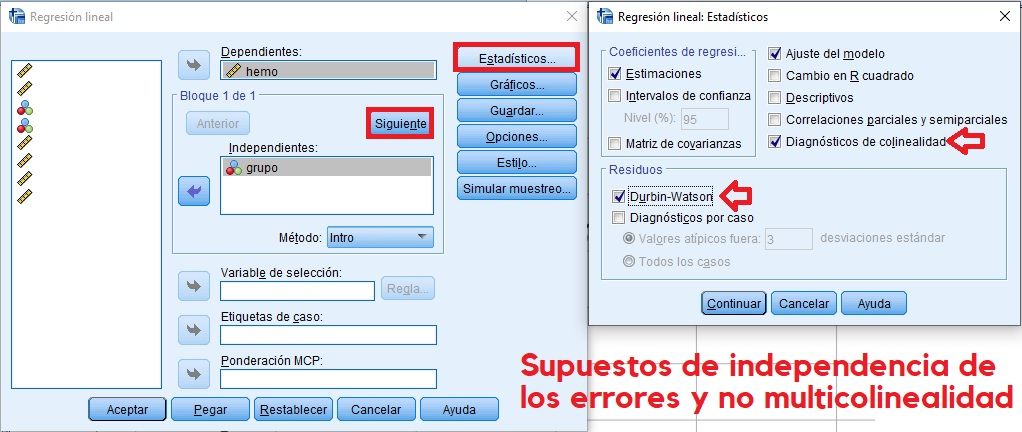
Regresión mútiple jerárquica en la que las variables explicativas (independientes) van entrando a formar parte del modelo en función de la correlación con la dependiente, activando la casilla de verificación para comprobar el cumplimiento del supuesto de partida de independencia de los errores de Durbin-Watson, y el de no multicolinealidad entre las variables independientes, es decir, que no aporten información redundante.
No tener en cuenta los NS/NC y los missing en los análisis estadísticos

Después de declarar los valores missing como 99 en vista de variables, se recodifica en la misma o distintas variables, todas las celdas vacías, con valores perdidos por el sistema o el usuario como 99.

Para el ejemplo de esta variable dicotómica, solo se tienen en cuenta los valores 0 o 1 (operador lógico o: |). Otra opción para el mismo resultado, sería ‘Seleccionar los casos si la opción’ cuya variable en cuestión sea distinto de 99 (<>99).
Reemplazar los puntos (valores perdidos por sistema) por 99

Problemas en Chi-cuadrado con frecuencias esperadas menor de 5 superior al 20%
Si el número de casillas con frecuencia esperada es menor de 5 supera el 20%, aparece una nueva columna con la significación exacta, que es la que se interpreta como p-valor en este caso.
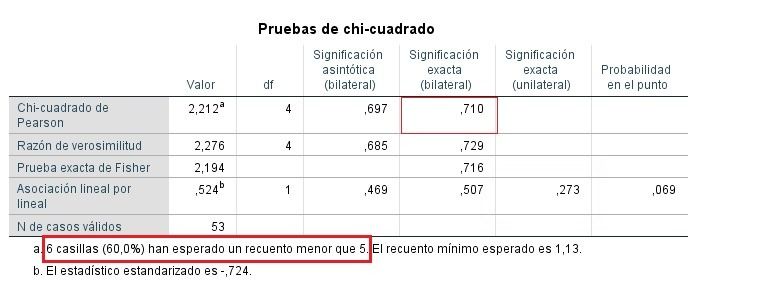
Chi-cuadrado con frecuencias ponderadas
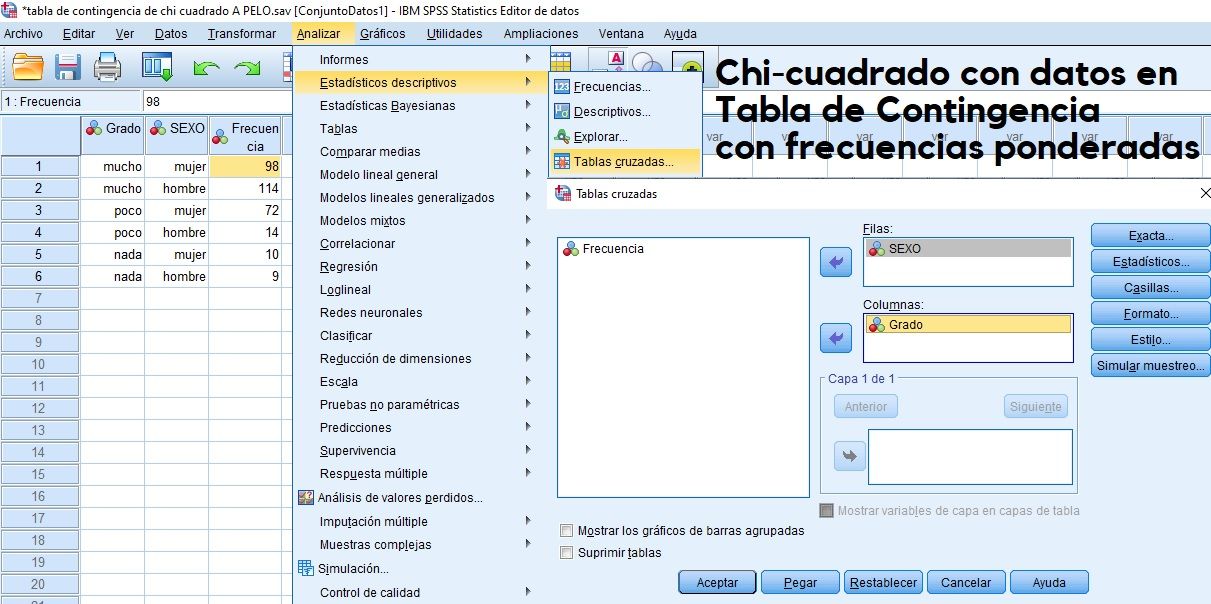
La variable independiente se suele colocar por Filas, y en el botón ‘Casillas’, seleccionamos también ‘por Filas’, para que se reflejen los porcentajes (probabilidades) de cada categoría de la variable dependiente, respecto a la variable independiente (probabilidad condicionada).
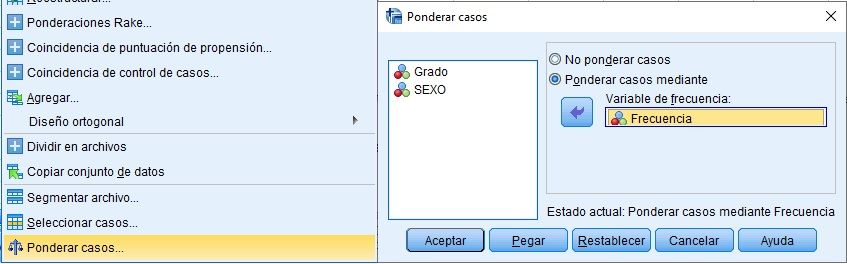
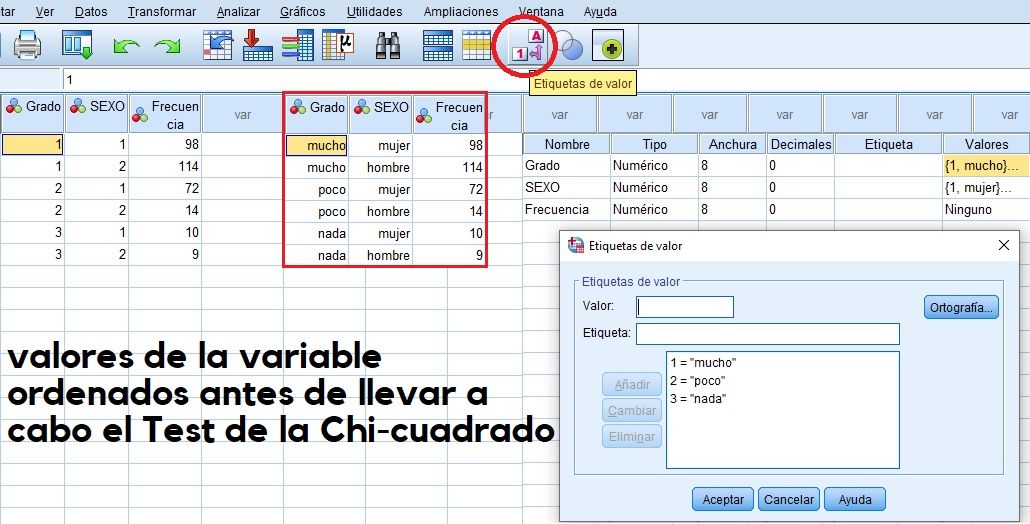
Chi cuadrado con frecuencias ponderadas previamente, a partir de las frecuencias observadas obtenidas de la Tabla de Contingencia. Es importante el orden a la hora de definir las variables:
Contraste de 2 proporciones con Tablas Cruzadas


El que las letras con los círculos (la ‘a’ y la ‘b’) sean diferentes implica que se aprecian diferencias estadísticamente significativas. Si fueran las 2 letras ‘a’ (la misma letra), no se mostrarían diferencias significativas entre el grupo control y el grupo experimental. Esta es la opción para comparar 2 porcentajes (proporciones) con el paquete estadístico SPSS.
CONTRASTE DE % EN SPSS V.28
Recodificar variables de más de 2 categorías en dicotómicas, en caso de no disponer de muchos casos (muestras pequeñas)

Recodificar en dicotómica, de cara a un test de independencia la Chi-cuadrado o Fisher, de cruce de 2 variables categóricas (detectar posibles correlaciones entre variables nominales), cuando haya más del 20% de casillas de frecuencias esperadas menores de 5, lo que suele ocurrir con variables con varias categorías y pocos casos.
Utilizar Test no Paramétricos en variables ordinales
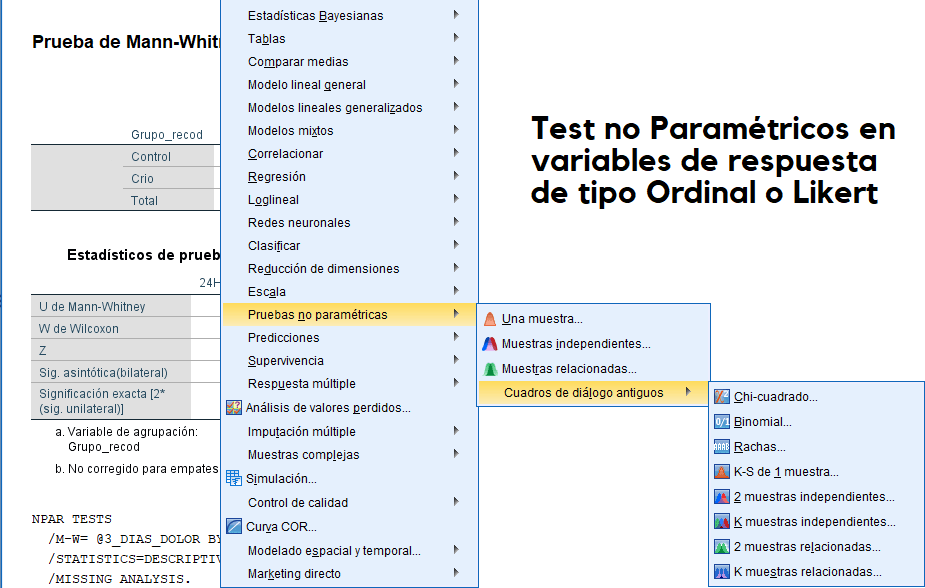
Test no paramétricos ante mediciones de variables dependientes o de respuesta en escala ordinal o likert (notas, encuestas de opinión, etc), sin necesidad de llevar a cabo la prueba de normalidad.
Graficar 2 variables dicotómicas


Histograma con curva Normal
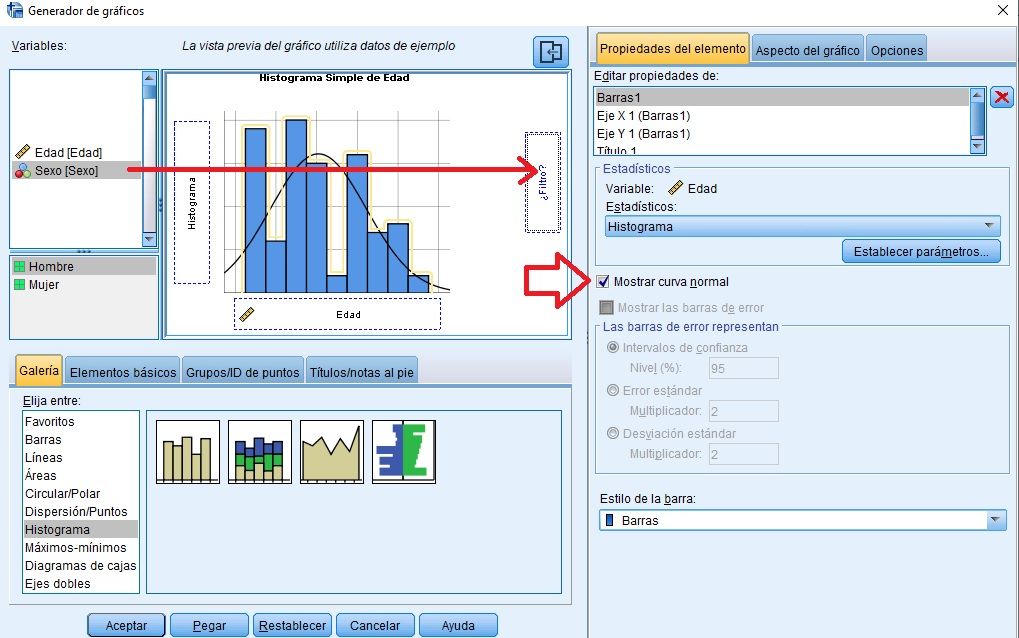
Histograma con valores en %

Histograma con Línea de Interpolación


Pruebas Post-Hoc de comparaciones múltiples no paramétricas (Kruskal-Wallis)
Meta-Análisis en SPSS 28
Bootstrapping: Simulación de Muestreo
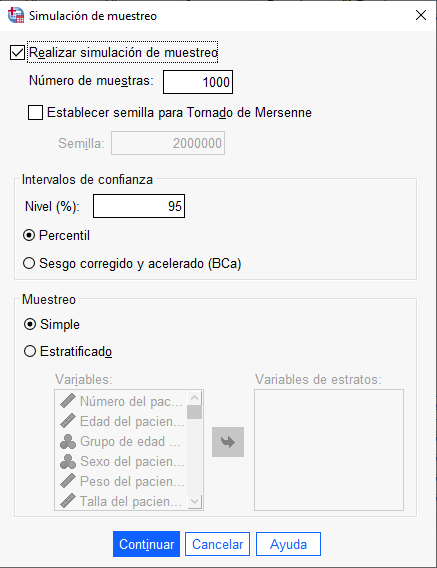
Haciendo clic en la opción Sesgo corregido y acelerado conseguimos simular 1000 muestras, lo que puede llevar a la significatividad estadística de factores cercanos a ser estadísticamente significativos en la muestra piloto del TFG, TFM (Master) o Tesis, en análisis estadísticos como la regresión logística binaria, ANCOVA, etc.
Calculadora Riesgo Relativo, Sensibilidad, Especificidad
Aunque tanto la Odds Ratio, para estudios transversales y para casos control, como el Riesgo Relativo, para ensayos clínicos o de cohortes (longitudinales), se pueden llevar a cabo a través de SPSS, la red internet nos ofrece algunas webs con calculadoras ya pre-configuradas, en las que tan solo hay que introducir los valores de las frecuencias de las tablas de contingencia, que se pueden obtener de manera sencilla con los comandos de Tablas Cruzadas de SPSS: