


Clases de estadística online, con el paquete estadístico SPSS, a cualquier nivel, a nivel individual o grupos. Consultoría y/o asesoría estadística sobre cualquier duda en TFG (trabajo de fin de grado), TFM (trabajo de fin de master), Tesis Doctoral, Abstract científico, etc. También clases online con Minitab, Statgraphics, Gretl o Stata.
Clases de SPSS online

Índice del Artículo
Outliers
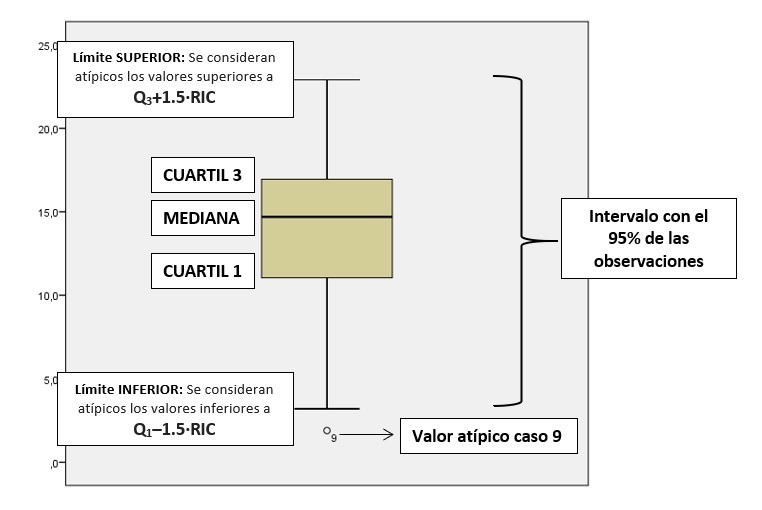
Los casos con valores atípicos se descartan del estudio para que no desvirtuar los resultados de los análisis y test de hipótesis estadísticos.

Descriptivos

T de Student

En la comparativa de igualdad, aumento o reducción de los valores de la media de la variable dependiente respecto de ambos grupos o tratamientos (variable explicativa o independiente) mediante una T de Student, siempre partiendo de la base de que se cumplen los supuestos de partida de cualquier contraste de hipótesis paramétricos: independencia de las observaciones, normalidad y homogeneidad de varianzas en la variable de respuesta en estudio. Si el p-valor asociado al estadístico de la T de Student del contraste es menor que 0.05 (alfa del 5% fijado para la investigación), si las diferencias resultan estadísticamente significativas, se rechaza la hipótesis nula, y por tanto las conclusiones giran entorno a la alternativa fijada para la investigación, ya sea bilateral, unilateral derecho o de cola izquierda:
H0: µ1 = µ2
H1 : µ1 DISTINTO µ2
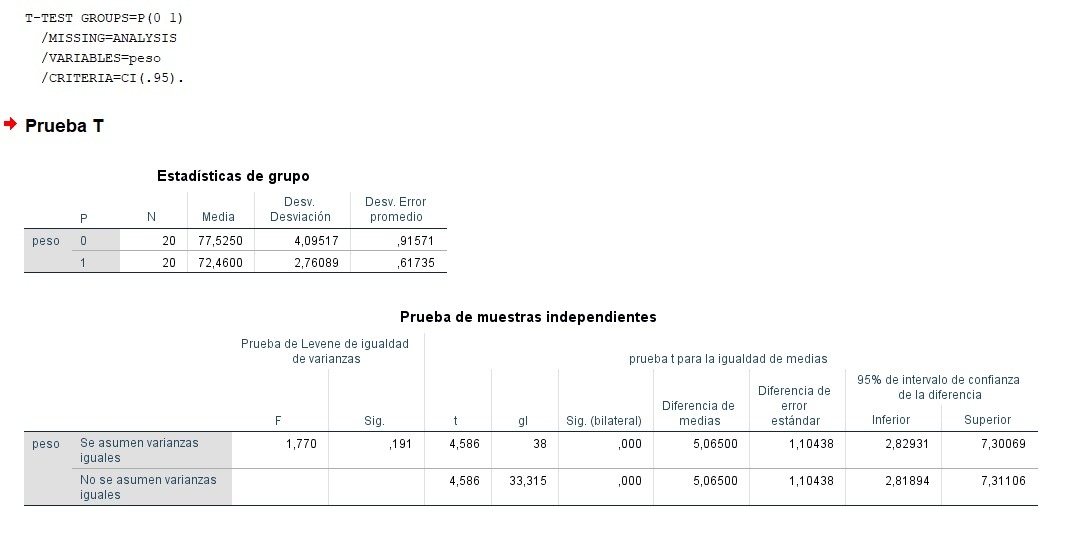

U de Mann-Whitney
En el caso de que no se cumplan alguno de los supuestos de partida de contraste paramétrico de la T de Student, el tamaño muestral sea menor de 50, o escala de la variable sea tipo ordinal o Likert, se construye el correspondiente test no paramétrico, esto es, la U de Mann-Whitney, contraste de comparativa de medianas o de suma de rangos positivos y negativos, con las mismas conclusiones respecto al p-valor y significatividad estadística que con el T-Test, aunque el parámetro de tendencia central ahora a contrastar es la mediana poblacional, en lugar de las medias del caso anterior.
H0: Me1 = Me2
H1 : Me1 DISTINTO Me2
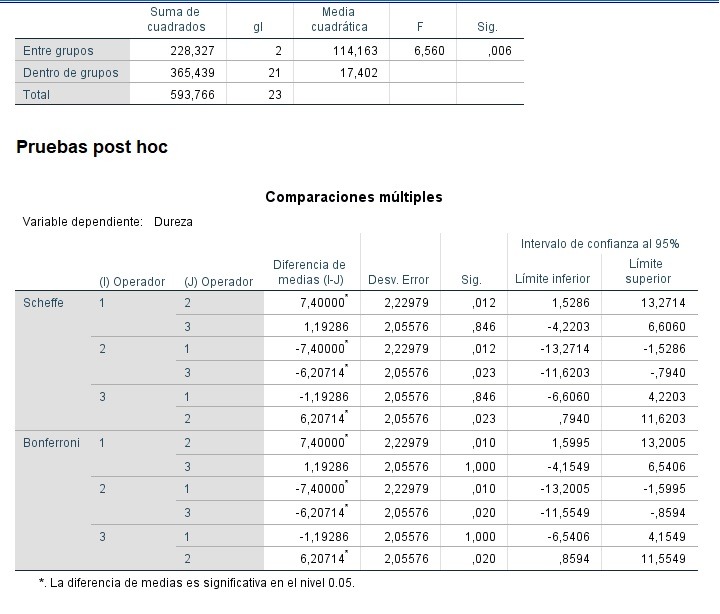
ANOVA
En el supuesto de que la Tabla ANOVA resulte estadísticamente significativa (p-valor<0,05), lo que viene a ser, se muestran diferencias significativas en al menos un par de medias de la variable dependiente en los grupos, se procede a llevar a cabo la pruebas de comparaciones múltiples con el método que se considera más adecuado, dada la naturaleza y los tamaños de las muestras. Cuando el p-valor asociado a cada cruce de medias mediante estas pruebas Post Hoc sea menor que 0,05, se demuestra que se hay diferencias estadísticamente significativas entre esos 2 grupos, siempre con 95% de confianza, considerando un nivel de significación α = 0,1 (10%), (excepcionalmente alto),solo en el caso de disponer de pocos datos.
Hipótesis nula (H0): µ1 = µ2 = µ3=… µn (las medias de la dependiente, en los 3 o más grupos, son iguales)
Hipótesis alternativa (H1): algún par de medias es diferente (no todas las medias son iguales)
Posible solución a problemas con el supuesto del cumplimiento de homocedasticidad en el ANOVA:

Kruskal-Wallis
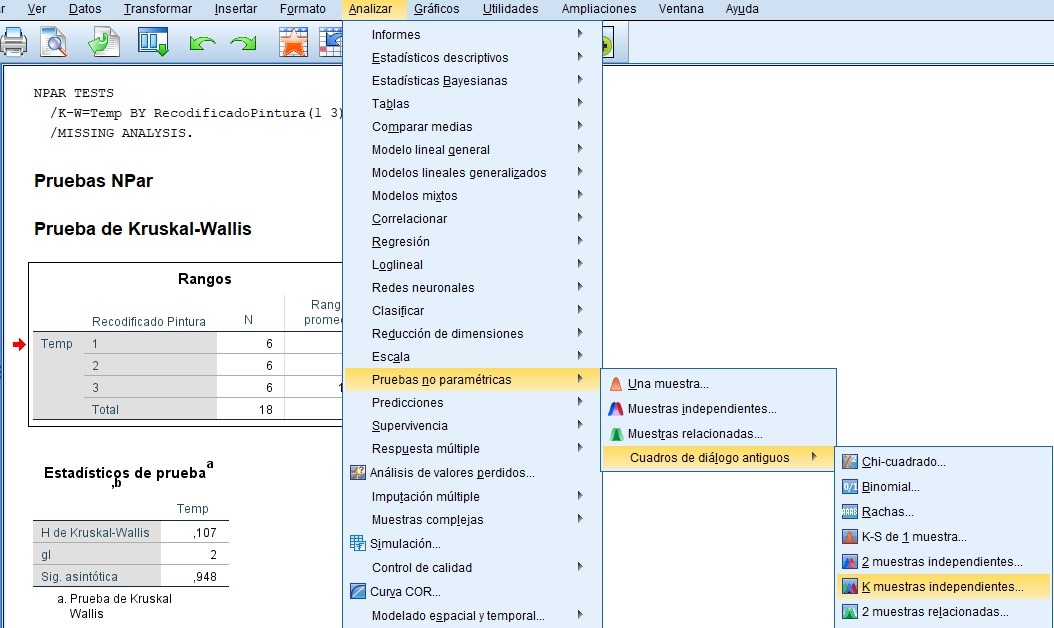
En el caso de violación grave de alguno de los supuestos paramétricos del ANOVA, se procede a llevar a cabo el equivalente no paramétrico, esto es, Kruskal-Wallis, contraste de comparativa de medianas, En el caso de resultar significativa esta prueba, se procede a comparar las medianas de los grupos 2 a 2 mediante el Test de la U de Mann-Whitney, para detectar las diferencias estadísticamente significativas a valor p menor de 0,05.
Regresión Logística Binaria

Se puede llevar a cado una regresión logística binaria para determinar la probabilidad de ocurrencia de la variable dependiente de respuesta dicotómica, en función de las variables explicativas numéricas, dicotómicas, o si se trata de variables de tipo nominal de 3 o más categorías, variable recodificadas en dummies, o lo que es lo mismo, dicotómicas con valores 0 y 1.
Un convenio bastante utilizado, es que la que proporción de la variabilidad de la dependiente explicada por el modelo logístico binario oscila entre el R2 de Cox-Snell y el R2 de Nagelkerke. Para que el modelo logístico binario se considere un buen modelo predictivo, tanto la R2 de Nagelkerke tiene que ser lo suficientemente importante (explicar lo máximo posible del % de la variabilidad de variable de respuesta, esto es, un valor lo más próximo a 0,6 o 0,7). Además el Test de bondad del ajuste de Hosmer-Lemeshow tiene que resultar estadísticamente significativo, esto es, el p-valor asociado debe de ser mayor que 0,05.
Una vez se comprueba que el modelo logístico binario es un buen ajuste, se procede a analizar cada uno de los coeficientes de las variables explicativas (exponencial de cada Beta, si es menor que 0 será de disminución, si es mayor que 0 , será de aumento de probabilidad de ocurrrencia del valor 1 de la dependiente) y su significatividad estadística, siendo buenos predictores si superan el valor p de 0,05, y cual es su interpretación con la probabilidad de ocurrencia de la variable dependiente dicotómica, de presencia o no del evento del análisis logístico.
estamatica@gmail.com