

Depuración de Datos
La depuración de datos previa a análisis estadísticos, es un faceta tan o más importante que el propio contrate de hipótesis posterior, ya se en una TFM (Trabajo de Fin de Master), TFG (Trabajo de Fin de Grado), Tesis, Maestría, Doctorado, Abstract científico para publicación, Paper para presentación, etc.
Índice del Artículo
Depuración de la Base de Datos

Seleccionar todos los valores a reemplazar (¡ojo!: valores, no nombres de las variables, etc) y sustituir el valor en blanco, o punto (.) o 0 por el valor 99, y de esta manera facilitar el trabajo posterior cuando se exporte la base de datos al software estadístico a utlilizar en el análisis, en el cual se definirán los valores missing (perdidos) como 99 o similar.
Eliminación de Outliers
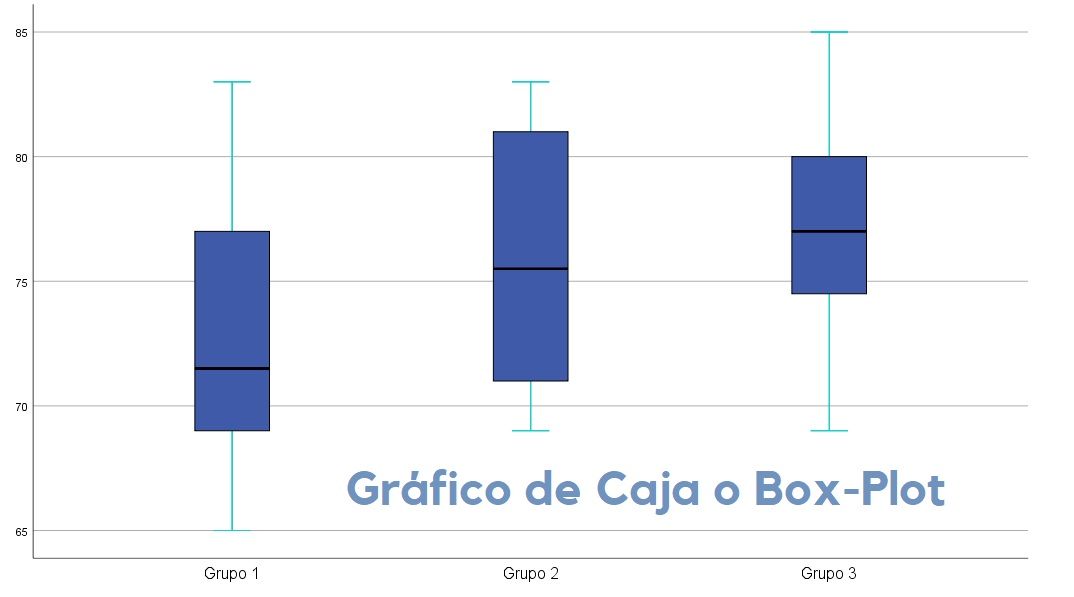
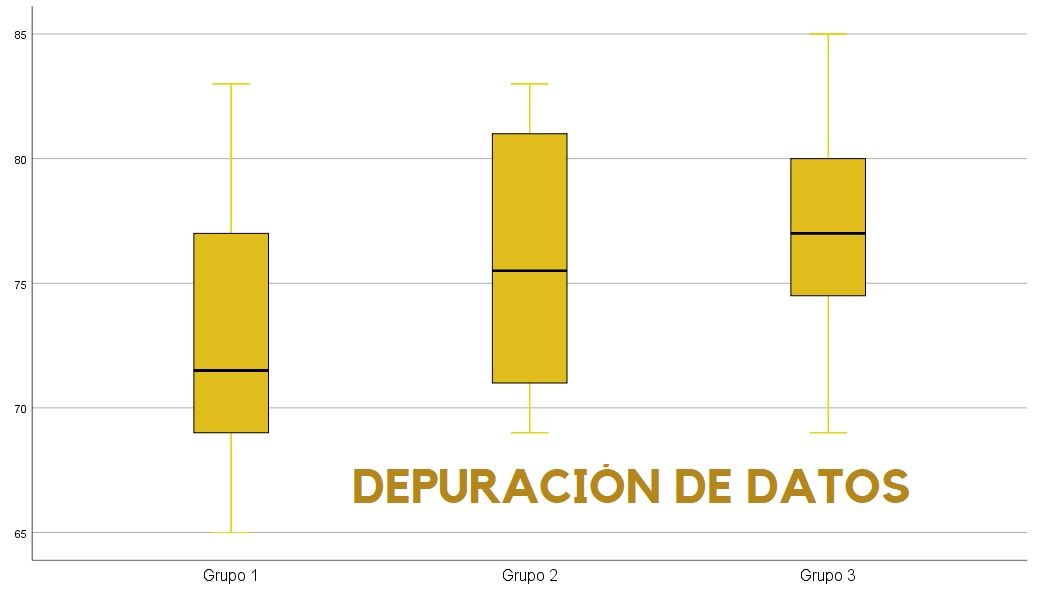
Se deben eliminar de nuestros estudio los casos atípicos o outliers que pueden desvirtuar el resultado y las conclusiones de los análisis estadísticos a llevar a cabo en la investigación. El propio gráfico o diagrama de cajas y bigotes o gráfico Box-Plot señala con un círculo los casos (filas) que se consideran atípicos, y que se considera importante no tener en cuenta para el análisis posterior, salvo que el tamaño muestral se considere lo suficientemente pequeño, como es el caso de las muestras piloto.


Recodificación de Variables en SPSS
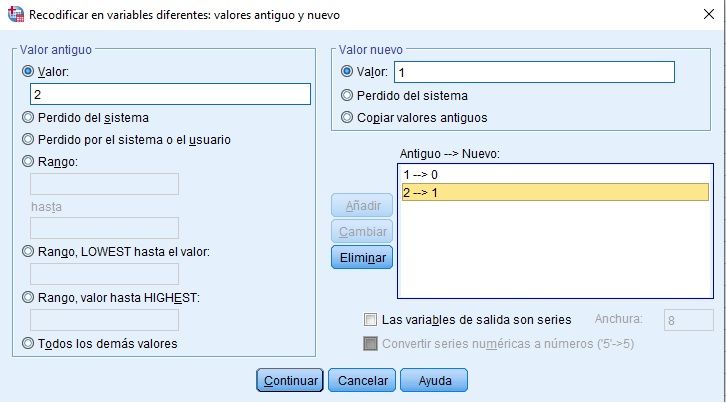

Existe la opción de recodificar en las mismas o en distintas (nuevas) variables, y de esta manera conseguir variables dicotómicas (ejemplo 0: NO, 1:SÍ), o politómicas de más de 2 categorías.
Eliminar casos que cumplen o no una determinada condición
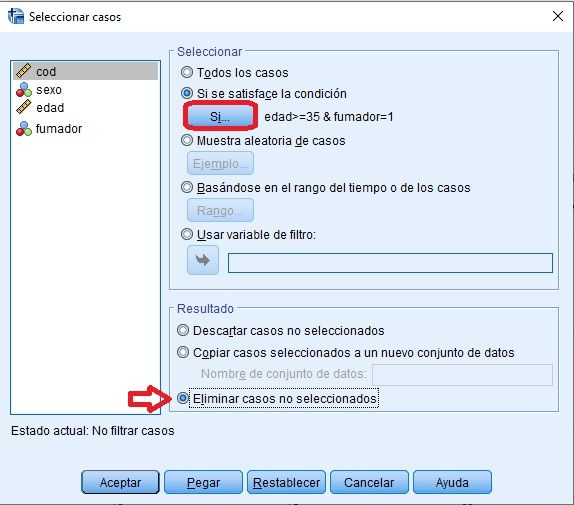
Seleccionar casos que cumplen o no una determinada condición
Seleccionar casos si cumplen una o varias condiciones en SPSS:

Segmentar archivos en SPSS
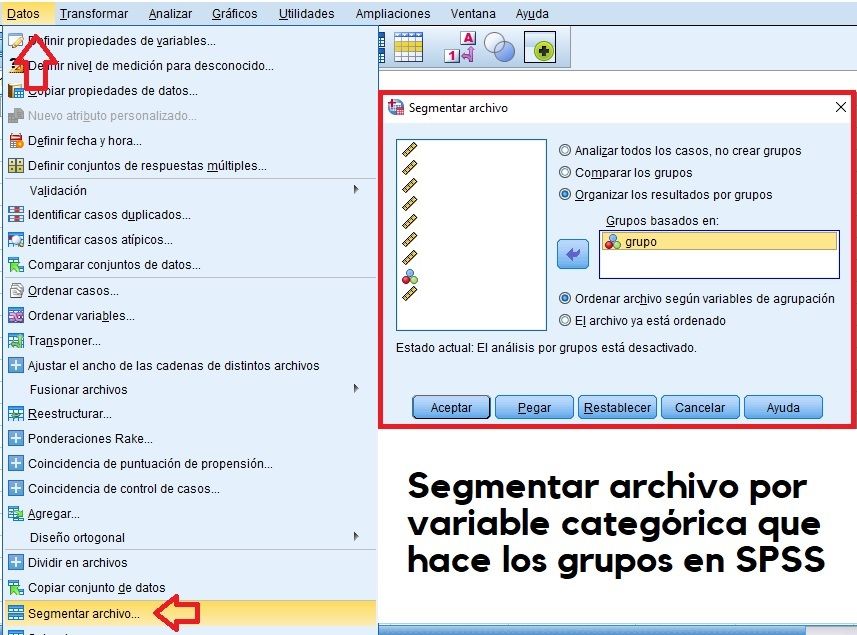
Cuando se trata de que los resultados de los estadísticos descriptivos, análisis estadísticos, etc, se muestren segmentados por una variable de interés que hace los grupos.