

ANCOVA (Análisis de la Covarianza)
Una variación del ANOVA cuando se dispone de una variable continua adicional que creemos que podría estar relacionada con la variable dependiente de respuesta. Esta variable adicional se puede añadir al análisis como una covariable, en el análisis de la covarianza (ANCOVA).
Se trata de detectar si la variable independiente, explicativa o Factor de 2 categorías (grupos) o más, influye en la variable dependiente, una vez eliminada la influencia de una covariable cuantitativa continua (de ahí el nombre de ANCOVA). Una de las categorías del factor puede tratarse del grupo control, en Bioestadística o Psicometría, por ejemplo. Al tratarse de una extensión de la Tabla ANOVA, la variable independiente categórica puede tener más de 2 niveles o tratamientos, o ser de tipo ordinal.
Índice del Artículo
Supuestos ANCOVA
- Los intrínsecos a cualquier modelo ANOVA paramétrico: Normalidad y homocedasticidad.
- Independencia entre la covariable cuantitativa (por ejemplo la edad) y las variables explicativas (la principal la nominal que conforma los 3 o más grupos del ANOVA)
- Homogeneidad de los coeficientes de regresión o pendientes (interacción del modelo ANCOVA no significativa, esto es p-valor <0,05), que no exista multicolinealidad (información redundante) entre la variable dependiente de respuesta y la covariable continua (coeficiente de correlación no demasiado importante).
- Linealidad entre la variable dependiente y la covariable
Gráfico de Dispersión


Una vez eliminados los casos atípicos, se grafica el Diagrama de Dispersión para comprobar el supuesto de linealidad:


Correlaciones | Colinealidad
Se trata de descartar el que ambas variables numéricas (continuas), la dependiente y la independiente, y las independientes entre sí, aporten información redundante (colinealidad). No se detectan problemas de multicolinealidad entre la variable dependiente y la covariable, realizando en correspondiente análisis de correlaciones, ya que aunque la correlación sea estadísticamente significativa al 5% (que es de lo que se trata), el grado de relación a través del coeficiente de correlación de Pearson es menor de 0,7-0,8, incluso está por debajo de 0,5, valor que empieza a considerarse como correlación importante en ciencias como la Psicología:


Modelo Univariado con SPSS


Se comprueba la interacción de la variable explicativa y la covariable numérica cuantitativa (seleccionando ambas variables), para comprobar si efectivamente resulta no significativa y se cumple el supuesto de partida del ANCOVA:


En la ventana de resultados de SPSS nos fijamos en el valor de probabilidad asociada a la interacción para comprobar el supuesto de interacción no significativa (0,316>0,05), como se pretendía demostrar con este análisis estadístico, es decir, se cumple el supuesto de homogeneidad de los coeficientes de regresión (‘Betas’).
Simulación de muestreo
En el caso de problemas en el cumplimiento de alguno de los supuestos de ANCOVA, se recurre a técnicas como la simulación de muestreo o técnicas de bootstrapping (bootstrap), que viene a ser un método de re-muestreo propuesto por Bradley Efron en el año 79, para poder aproximar la distribución en el muestreo de un estadístico.

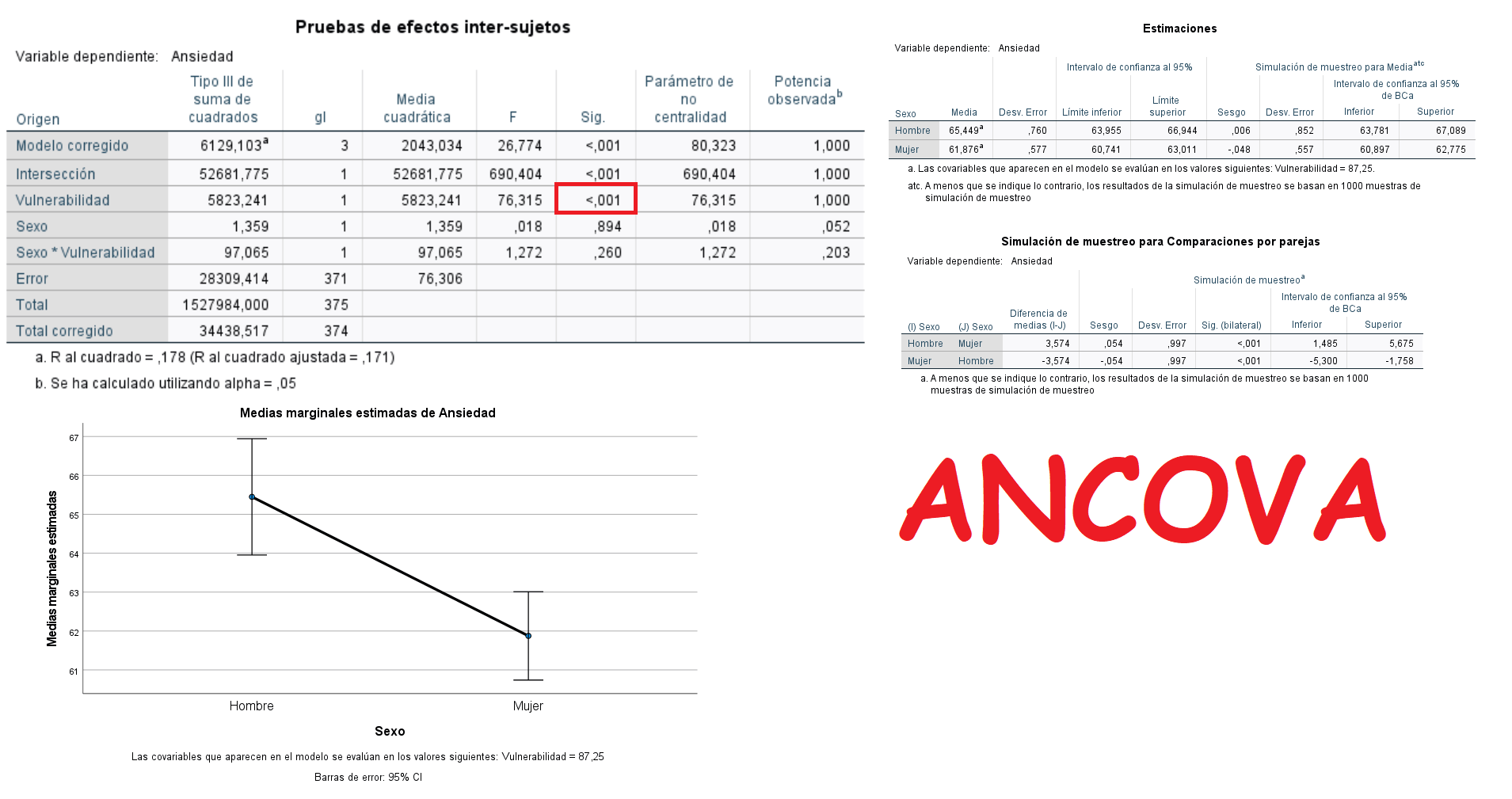
Medias marginales estimadas
Se trata de ver si hay diferencias en medias en la variable dependiente en cuanto a los niveles del factor, eliminando previamente la influencia en los niveles o tratamientos del factor de la covariable numérica.


Dentro de la propia comprobación de los supuestos de partida del ANCOVA, la prueba de homogeneidad de varianzas de Levene arroja unos resultados en torno a que la variabilidad de la variable de respuesta en estudio, es similar entre los niveles de la variable cualitativa (o cualitativas) que se hayan introducido en el modelo. En este caso el p-valor=0,379>0,05, resulta no significativo, por lo que no se puede rechazar la hipótesis de homocedasticidad.

El tamaño del efecto queda reflejado en la columna del ‘eta parcial al cuadrado’ (% de variabilidad explicada por cada variable explicativa), la variable de respuesta está más vinculada al Factor categórico (explica el 13,2% de la variabilidad) que a la Edad (el 8,4%); y la % de variabilidad global explicada por el modelo se comprueba con el R al cuadrado ajustado (15,9% en el ejemplo)
Las medias marginales estimadas de los 3 tratamientos después de eliminar el efecto de la covariable o covariables, se reflejan en la siguiente tabla de la salida de resultados del ANCOVA, además de que la prueba de comparaciones múltiples POST-HOC de Sidak, la más conveniente en este tipo de análisis estadístico, no resulta estadísticamente significativa para ninguno de los 3 grupos que conforman el factor, pues ninguna probabilidad asociada es menor de 0,05 en los cruces 2 a 2:

Si se trabaja con las últimas versiones de SPSS (v.27, v.28 o v.29), un ejemplo de cuadro de diálogo de la simulación de muestreo o bootstrapping con las medias marginales graficadas, sería de la forma:

*IMPORTANTE: SI SE UTILIZAN LAS TÉCNICAS DE SIMULACIÓN DE MUESTREO, NO SE VISUALIZAN LOS GRÁFICOS DE MEDIAS MARGINALES