

Binary Logistic Regression with SPSS
Binary Logistic Regression to predict the probability of occurrence of a certain dichotomous dependent variable with respect to the groups that form other independent, categorical and / or continuous variables, and in the case of nominal with several categories, recoded into dummy (dichotomous). It establishes a logit prediction or adjustment model, very suitable, therefore, in studies of groups in Biostatistics or Social Sciences, to determine the probability of disease occurrence, the positive effect or not of treatments (0: NO; 1: YES) , operation or not of a policy, or of a marketing campaign, etc.
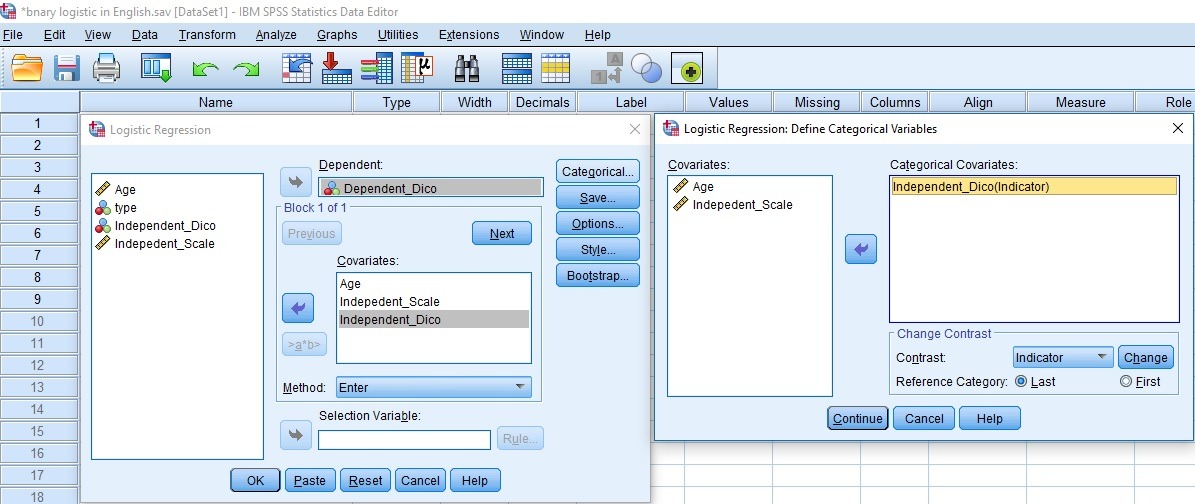
Categorical / nominal type variables, such as gender, are defined separately. Variables that have more than 2 categories, if considered of vital importance for our statistical analysis, are recoded in a special way into dummies, dichotomous variables of values 0 and 1.
Índice del Artículo
How to recode DUMMY Variables in SPSS?

To be able to introduce a nominal variable of this type, which has 3 categories (or more), in the model we must resort to the “dummy” categorization, which consists of the generation of dummy dichotomous variables for the different categories of the variable. The coding scheme that is used to create, and therefore, recode into a dummy a categorical or ordinal variable with more than 2 categories (example: Level of Studies), taking into account that the reference category is “Primary Studies” , so that it can become part of the binary logistic regression it is of the form, that is, 2 dummy variables are generated for 3 categories, 3 for 4 categories, the omitted category remaining as reference variable:
Primary | 0 | 0 |
Secondary | 1 | 0 |
University | 0 | 1 |
Then by having 3 categories in the variable level of studies, we generate 2 variables, Secondary and University. If the individual belongs to the Primary category, we give 0 value to each of these 2 dummies created.
RECODIFY IN DIFFERENT VARIABLES
We proceed to generate 2 new dummies variables, using the Transform: Recode into different variables. Recode into different variables with SPSS, variable with 6 categories is recoded into 5 dummies variables, taking as reference the first category or a concret category…
Binary Logistic Regression Model

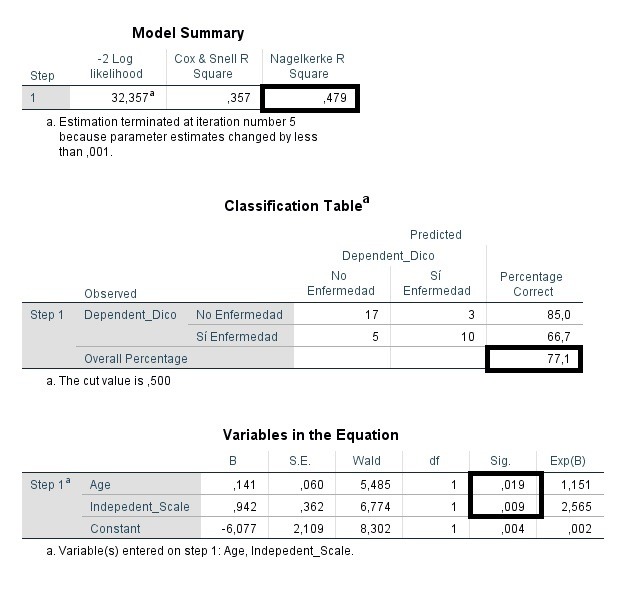
With the Hosmer-Lemeshow test, the logistic model is considered potable (0.631> 0.05), and explains 53.9% of the variability from the Nagelkerke R2 value, with these 3 variables becoming part of the same. The p-value associated with the explanatory variable ‘AGE’ is statistically significant (0.058 <0.1) only at 10% (sometimes 0.1 is the level of significance set for the investigation, if we have a small sample, or if the variable is considered relevant in the study), and the parameter value of 1,126 (> 0) inclines the probability of occurrence towards the value defined as 1 for the dichotomous response dependent variable. The p-value associated with the explanatory variable ‘Independent_Continuous’ is statistically significant at 5% (0.019 <0.05), and the parameter value of 2,419 (> 0) inclines the probability of occurrence towards the value defined as 1 for the dependent variable of dichotomous response. The Independent_Dicotomic variable, on the other hand, is not statistically significant in order to predict the model (0.125> 0.05).
A statistical analysis of multiple regression (both multivariate and logistic regression) must always be carried out, with all the covariates considered to be modified, for later, and in the case of all the non-statistically serious explanatory explanations in order to predict the model, a new regression eliminating independent variables that were not affected in the previous adjustment:
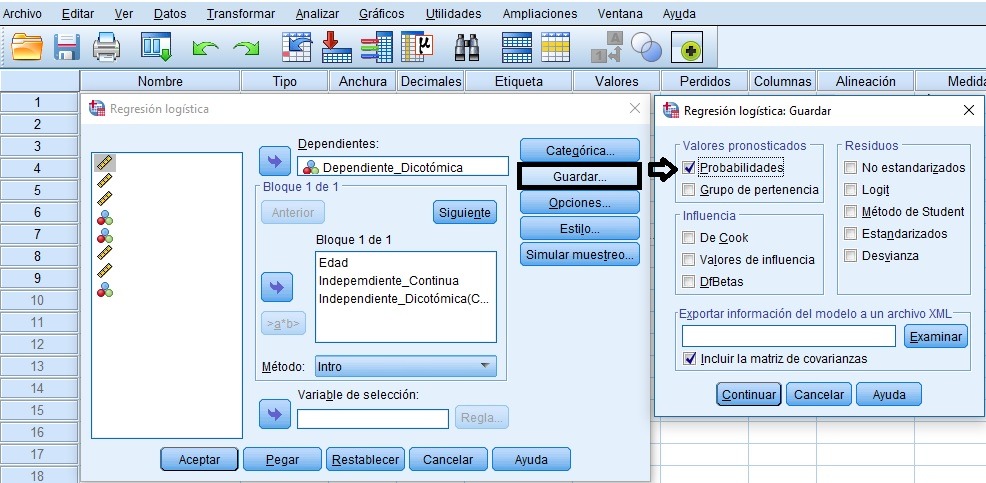
How to estimate the probability of occurrence of the dichotomous dependent from explanatory variables, giving values to them?

Prognosis of probability of cases / individuals:
‘dedicated to Augusto Carmona Mota, my father-in-law, who gave me the last boost to publish a post in English…’
estamatica@gmail.com